OSRD peut être utilisé pour effectuer deux types de calculs :
Calcul de marche (standalone train simulation) : calcul du temps de parcours d’un train sur un trajet donné, effectué sans interaction entre le train et le système de signalisation.
Simulation : calcul “dynamique” de plusieurs trains interagissant entre eux via le système de signalisation.
1 - Les données d’entrée
Un calcul de marche est basé sur 5 entrées :
L’infrastructure : Topologie des lignes et des voies, position des gares et bâtiments voyageurs, position et type des aiguilles, signaux, vitesses maximales de ligne, profil de ligne corrigée (pentes, rampes et virages).
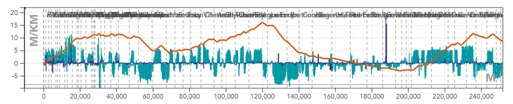
L’histogramme bleu est une représentation des déclivités en [‰] par position en [m]. Les déclivités sont positives pour les rampes et négatives pour les pentes.
La ligne orange représente le profil cumulé, c’est-à-dire l’altitude relative par rapport au point de départ.
La ligne bleue est une représentation des virages en termes de rayons des courbures en [m].
Le matériel roulant : Dont les caractéristiques nécessaires pour effectuer la simulation sont représentées ci-dessous.
La courbe orange, appelée courbe effort-vitesse du matériel, représente l’effort moteur maximal en fonction de la
vitesse de circulation.
La longueur, la masse, et la vitesse max du train sont représentées en bas de l’encadré.
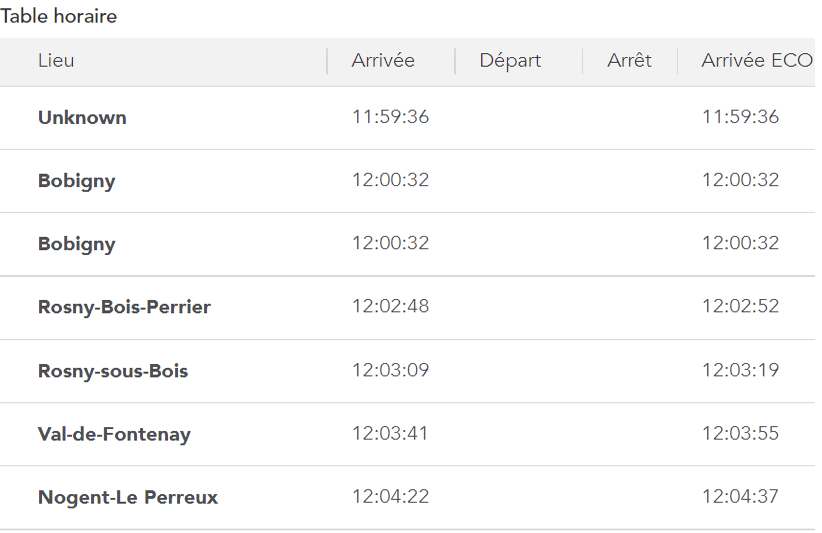
L’horaire de départ permettant ensuite de calculer les horaires de passage aux différents points remarquables (dont gares).
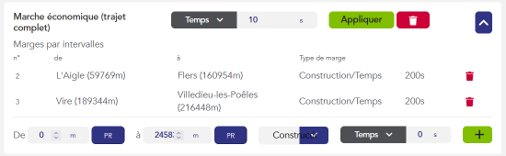
Les marges : Temps ajouté au trajet du train pour détendre sa marche (voir page sur les marges).
Les résultats d’un calcul de marche peuvent se représenter sous différentes formes :
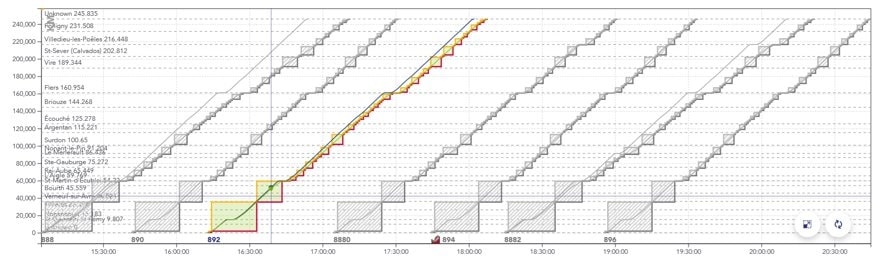
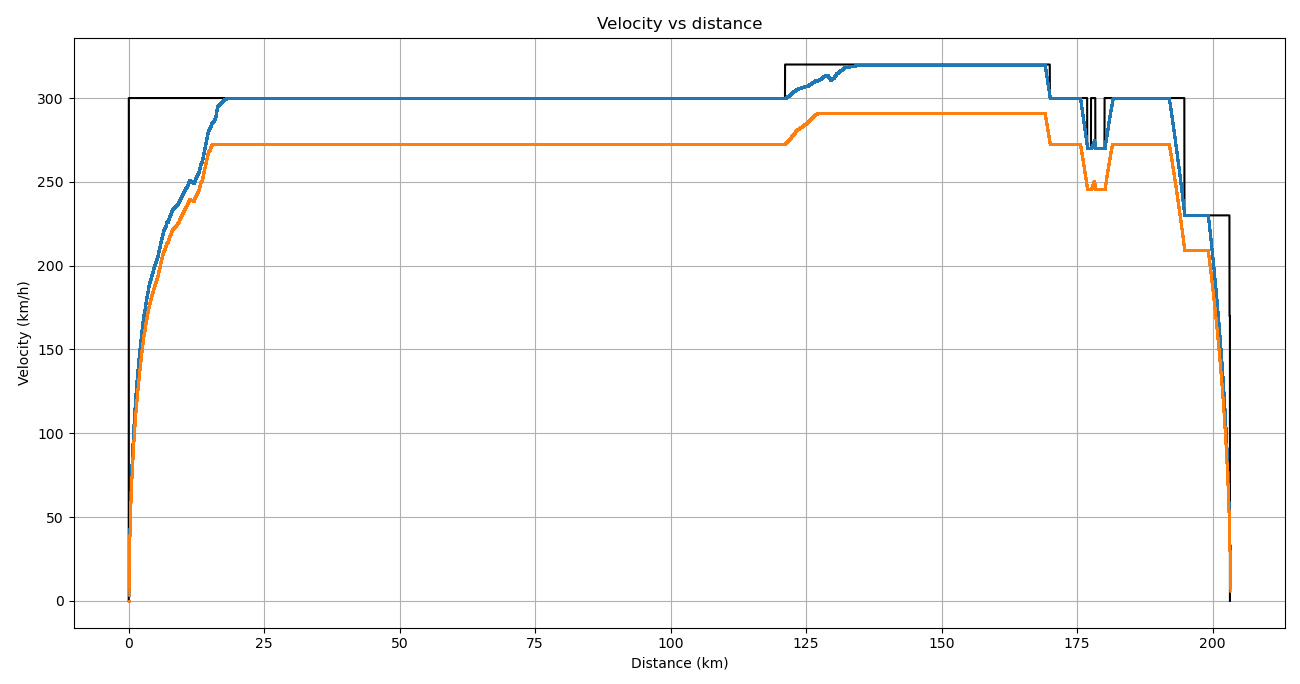
Le graphique espace/temps (GET) : représente le parcours des trains dans l’espace et dans le temps, sous la forme de traits globalement diagonaux dont la pente est la vitesse. Les arrêts apparaissent sous la forme de plateaux horizontaux.
Exemple de GET avec plusieurs trains espacés d’environ 30mn.
L’axe x est l’horaire de passage du train, l’axe y est la position du train en [m].
La ligne bleue représente le calcul de marche le plus tendu pour le train, la ligne verte représente un calcul de marche détendu, dit « économique ».
Les rectangles pleins entourant les trajets représentent les portions de la voie successivement réservées au passage du train (appelées cantons).
Le graphique espace/vitesse (GEV) : représente le parcours d’un seul train, cette fois-ci en termes de vitesse. Les arrêts apparaissent donc sous forme de décrochages de la courbe jusqu’à zéro, suivis d’un ré-accélération.
L’axe x est la position du train en [m], l’axe y est la vitesse du train en [km/h] .
La ligne violette représente la vitesse maximale autorisée.
La ligne bleue représente la vitesse dans le cas du calcul de marche le plus tendu.
La ligne verte représente la vitesse dans le cas du calcul de marche « économique ».
Les horaires de passage du train aux différents points remarquables
1 - Modélisation physique
La modélisation physique joue un rôle important dans le cœur de calcul d’OSRD. C’est elle qui nous permet de simuler la circulation des trains, et elle doit être aussi réaliste que possible.
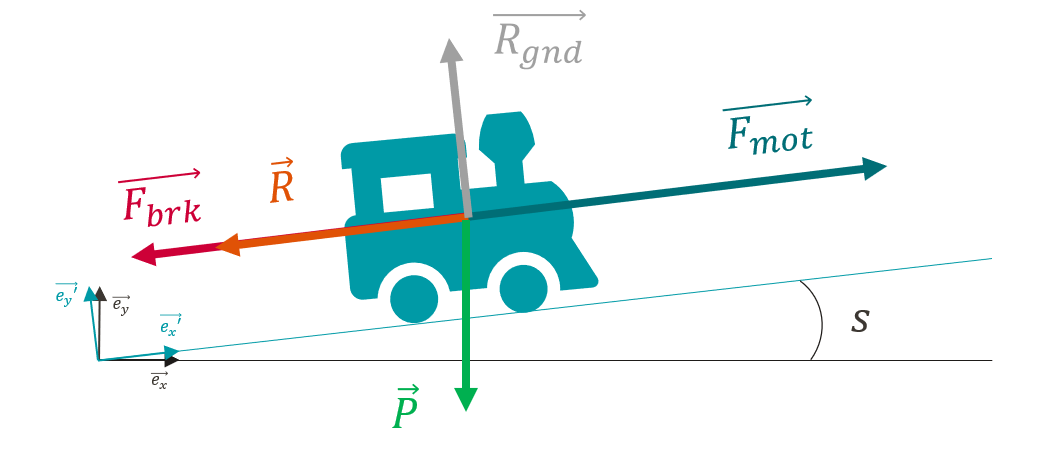
Bilan des forces
Pour calculer le déplacement du train au cours du temps, il faut d’abord calculer sa vitesse à chaque instant.
Une manière simple d’obtenir cette vitesse est de passer par le calcul de l’accélération.
Grâce au principe fondamental de la dynamique, l’accélération du train à chaque instant est directement dépendant
des différentes forces qui lui sont appliquées : $$ \sum \vec{F}=m\vec{a} $$
Traction : La valeur de la force de traction \(F_{mot}\) dépend de plusieurs facteurs :
du matériel roulant
de la vitesse du train \(v^{\prime}x\), selon la courbe effort-vitesse ci-dessous :
L’axe x représente la vitesse du train en [km/h], l’axe y, la valeur de la force de traction en [kN].
de l’action du conducteur, qui accélère plus ou moins fort en fonction de l’endroit où il se trouve sur son trajet
Freinage : La valeur de la force de freinage \(F_{brk}\) dépend elle aussi du matériel roulant et de l’action du conducteur mais possède une valeur constante pour un matériel donné. Dans l’état actuel de la modélisation, le freinage est soit nul, soit à sa valeur maximale.
Une seconde approche de la modélisation du freinage est l’approche dite horaire, car utilisée pour la production horaire à la SNCF. Dans ce cas, la décélération est fixe et le freinage ne dépend plus des différentes forces appliquées au train. Les valeurs de décélération typiques vont de 0.4 à 0.7m/s².
Résistance à l’avancement : Pour modéliser la résistance à l’avancement du train on utilise la formule de Davis qui prend en compte tous les frottements et la résistance aérodynamique de l’air. La valeur de la résistance à l’avancement dépend de la vitesse \(v^{\prime}_x\). Les coefficients \(A\), \(B\), et \(C\) dépendent du matériel roulant.
Poids (pentes + virages) : La force du poids donnée par le produit entre la masse \(m\) du train et la constante gravitationnelle \(g\) est projetée sur les axes \(\vec{e_x}^{\prime}\) et \(\vec{e_y}^{\prime}\).Pour la projection, on utilise l’angle \(i(x^{\prime})\), qui est calculé à partir de l’angle de déclivité \(s(x^{\prime})\) corrigé par un facteur qui prend en compte l’effet du rayon de virage \(r(x^{\prime})\).
Réaction du sol : La force de réaction du sol compense simplement la composante verticale du poids, mais n’a pas d’impact sur la dynamique du train car elle n’a aucune composante selon l’axe \({\vec{e_x}^{\prime}}\).
$$ \vec{R_{gnd}}=R_{gnd}{\vec{e_{y^{\prime}}}} $$
Equilibre des forces
L’équation du principe fondamental de la dynamique projetée sur l’axe \({\vec{e_x}^{\prime}}\) (dans le référentiel du train) donne l’équation scalaire suivante :
Celle-ci est ensuite simplifiée en considérant que malgré la pente le train se déplace sur un plan et en amalgamant
\(\vec{e_x}\) et \(\vec{e_x}^{\prime}\). La pente a toujours un impact sur le bilan des forces mais on considère que le train ne se déplace qu’horizontalement, ce qui donne l’équation simplifiée suivante :
La force motrice et la force de freinage dépendent de l’action du conducteur (il décide d’accélérer ou de freiner plus ou moins fort en fonction de la situation). Cette dépendance se traduit donc par une dépendance de ces deux forces à la position du train. La composante du poids dépend elle aussi de la position du train, car provenant directement des pentes et des virages situées sous ce dernier.
De plus, la force motrice dépend de la vitesse du train (selon la courbe effort vitesse) tout comme la résistance à
l’avancement.
Ces différentes dépendances rendent impossible la résolution analytique de cette équation, et l’accélération du train à chaque instant doit être calculée par intégration numérique.
2 - Intégration numérique
Introduction
La modélisation physique ayant montré que l’accélération du train était influencée par différents facteurs variant le long du trajet (pente, courbure, force de traction du moteur…), le calcul doit passer par une méthode d’intégration numérique. Le trajet est alors séparé en étapes suffisamment courtes pour considérer tous ces facteurs comme constants, ce qui permet cette fois ci d’utiliser l’équation du mouvement pour calculer le déplacement et la vitesse du train.
La méthode d’intégration numérique d’Euler est la plus simple pour effectuer ce genre de calcul, mais elle présente un certain nombre d’inconvénients. Cet article explique la méthode d’Euler, pourquoi elle ne convient pas aux besoins d’OSRD et quelle méthode d’intégration doit être utilisée à la place.
La méthode d’Euler
La méthode d’Euler appliquée à l’intégration de l’équation du mouvement d’un train est :
La méthode d’Euler a pour avantages d’être très simple à implémenter et d’avoir un calcul plutôt rapide pour un pas de temps donné, en comparaison avec d’autres méthodes d’intégration numérique (voir annexe)
Les inconvénients de la méthode d’Euler
La méthode d’intégration d’Euler présente un certain nombre de problèmes pour OSRD :
Elle est relativement imprécise, et donc nécessite un faible pas de temps, ce qui génère beaucoup de données.
En intégrant dans le temps, on ne connaît que les conditions du point de départ du pas d’intégration (pente, paramètres d’infrastructure, etc.) car on ne peut pas prédire précisément l’endroit où il se termine.
On ne peut pas anticiper les futurs changements de directive : le train ne réagit qu’en comparant son état actuel à sa consigne au même instant. Pour illustrer c’est un peu comme si le conducteur était incapable de voir devant lui, alors que dans la réalité il anticipe en fonction des signaux, pentes, virages qu’il voit devant lui.
La méthode Runge-Kutta 4
La méthode Runge-Kutta 4 appliquée à l’intégration de l’équation du mouvement d’un train est :
La méthode d’intégration de Runge Kutta 4 permet de répondre aux différents problèmes soulevés par celle d’Euler :
Elle permet d’anticiper les changements de directive au sein d’un pas de calcul, représentant ainsi davantage la réalité de conduite d’un train.
Elle est plus précise pour le même temps de calcul (voir annexe), permettant des étapes d’intégration plus grandes, donc moins de points de données.
Les inconvénients de la méthode de Runge Kutta 4
Le seul inconvénient notable de la méthode de Runge Kutta 4 rencontré pour l’instant est sa difficulté d’implémentation.
Le choix de la méthode d’intégration pour OSRD
Étude de la précision et de la vitesse de calcul
Différentes méthodes d’intégration auraient pu remplacer l’intégration d’Euler de base dans l’algorithme d’OSRD. Afin de décider quelle méthode conviendrait le mieux, une étude sur la précision et la vitesse de calcul de différentes méthodes a été menée. Cette étude sert à comparé les méthodes suivantes :
Euler
Euler-Cauchy
Runge-Kutta 4
Adams 2
Adams 3
Toutes les explications sur ces méthodes peuvent être trouvées dans ce document, et le code python utilisé pour la simulation est ici.
La simulation calcule la position et la vitesse d’un TGV accélérant sur une ligne droite plate.
Simulations à pas de temps équivalent
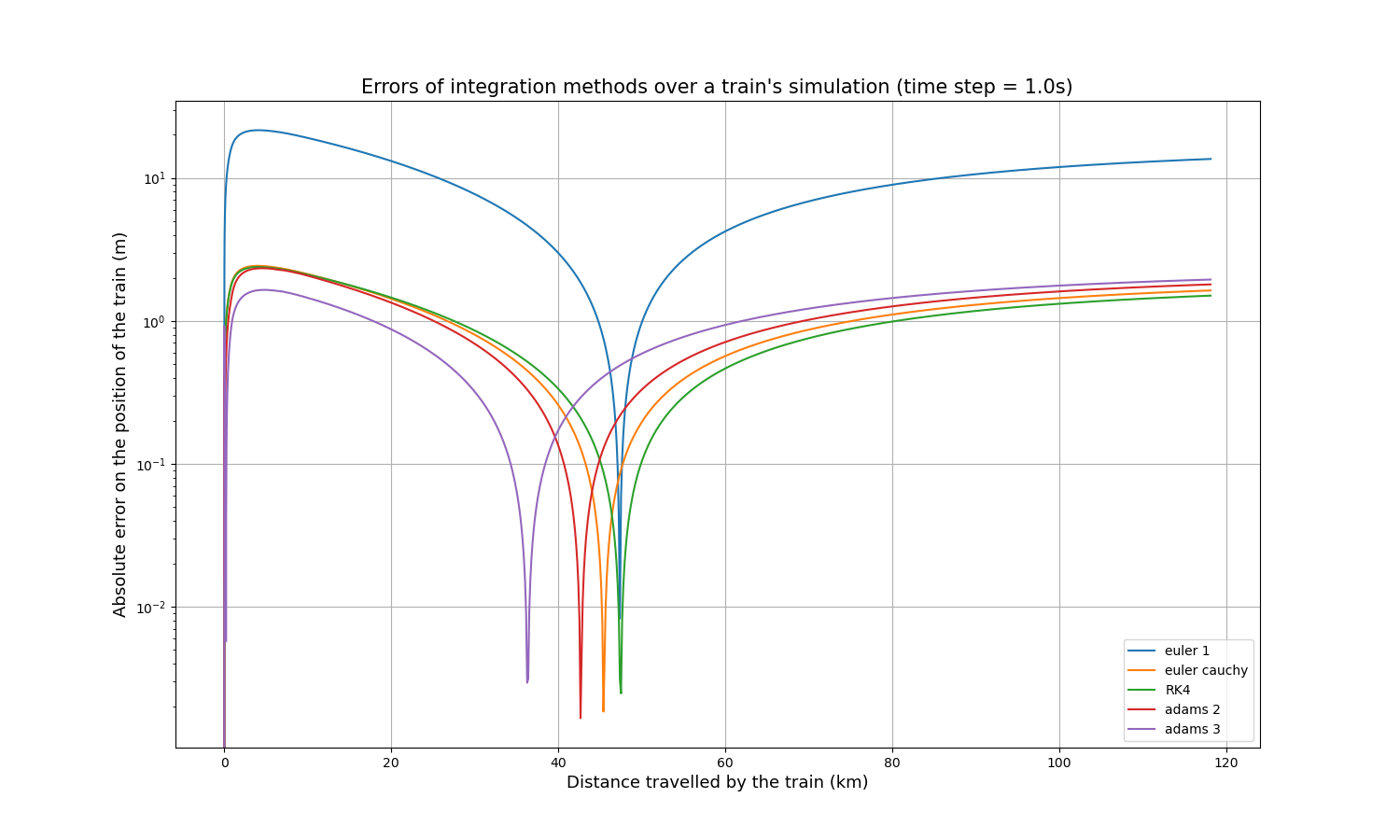
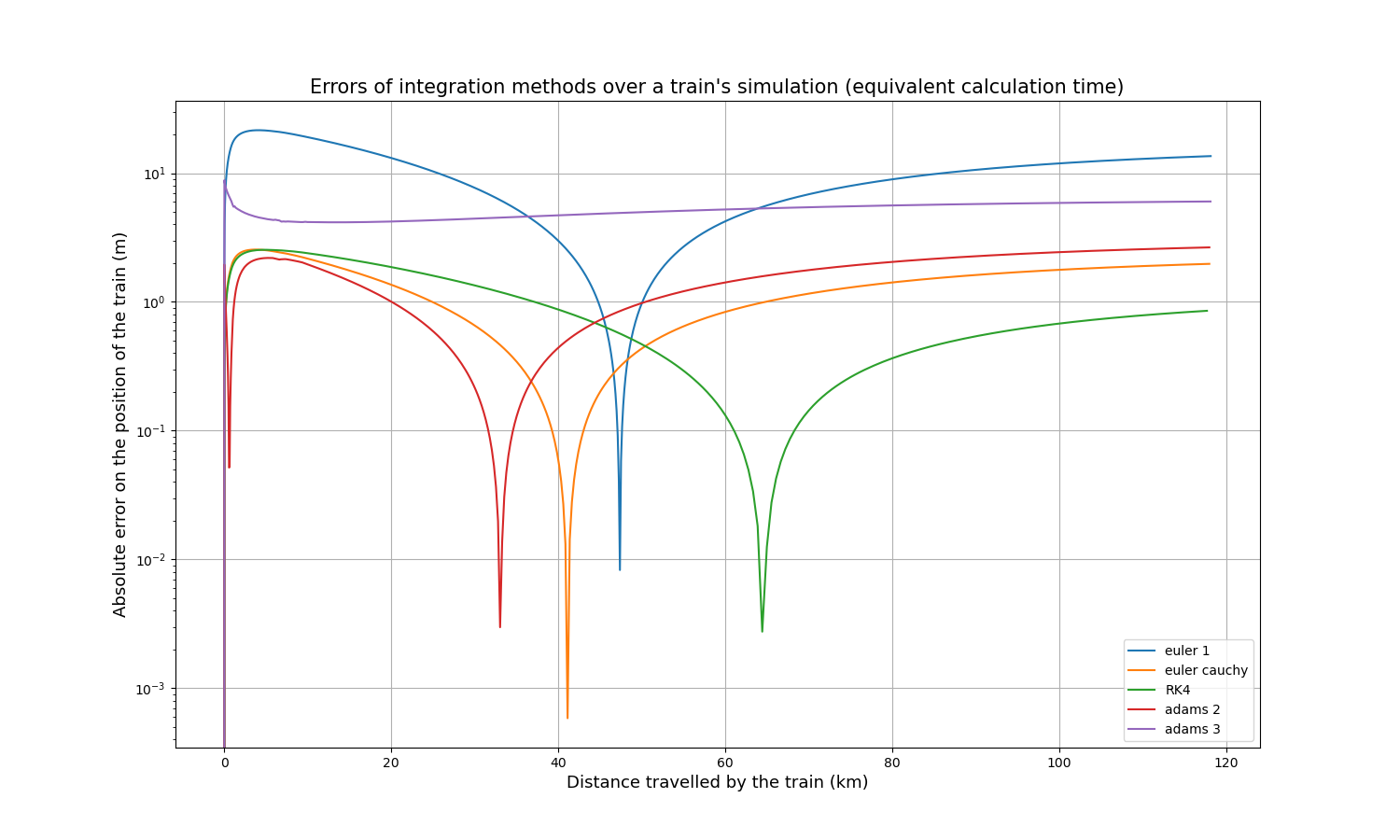
Une courbe de référence a été simulée en utilisant la méthode d’Euler avec un pas de temps de 0,1s, puis le même parcours a été simulé en utilisant les autres méthodes avec un pas de temps de 1s. Il est alors possible de comparer simplement chaque courbe à la courbe de référence, en calculant la valeur absolue de la différence à chaque point calculé. Voici l’erreur absolue résultante de la position du train sur sa distance parcourue :
Il apparaît immédiatement que la méthode d’Euler est moins précise que les quatre autres d’environ un ordre de grandeur. Chaque courbe présente un pic où la précision est extrêmement élevée (erreur extrêmement faible), ce qui s’explique par le fait que toutes les courbes commencent légèrement au-dessus de la courbe de référence, la croisent en un point et finissent légèrement en dessous, ou vice versa.
Comme la précision n’est pas le seul indicateur important, le temps de calcul de chaque méthode a été mesuré. Voici ce que nous obtenons pour les mêmes paramètres d’entrée :
Méthode d’intégration
Temps de calcul (s)
Euler
1.86
Euler-Cauchy
3.80
Runge-Kutta 4
7.01
Adams 2
3.43
Adams 3
5.27
Ainsi, Euler-Cauchy et Adams 2 sont environ deux fois plus lents que Euler, Adams 3 est environ trois fois plus lent, et RK4 est environ quatre fois plus lent. Ces résultats ont été vérifiés sur des simulations beaucoup plus longues, et les différents ratios sont maintenus.
Simulation à temps de calcul équivalent
Comme les temps de calcul de toutes les méthodes dépendent linéairement du pas de temps, il est relativement simple de comparer la précision pour un temps de calcul à peu près identique. En multipliant le pas de temps d’Euler-Cauchy et d’Adams 2 par 2, le pas de temps d’Adams 3 par 3, et le pas de temps de RK4 par 4, voici les courbes d’erreur absolue résultantes :
Et voici les temps de calcul :
Méthode d’intégration
Temps de calcul (s)
Euler
1.75
Euler-Cauchy
2.10
Runge-Kutta 4
1.95
Adams 2
1.91
Adams 3
1.99
Après un certain temps, RK4 tend à être la méthode la plus précise, légèrement plus précise que Euler-Cauchy, et toujours bien plus précise que la méthode d’Euler.
Conclusions de l’étude
L’étude de la précision et de la vitesse de calcul présentée ci-dessus montre que RK4 et Euler-Cauchy seraient de bons candidats pour remplacer l’algorithme d’Euler dans OSRD : les deux sont rapides, précis, et pourraient remplacer la méthode d’Euler sans nécessiter de gros changements d’implémentation car ils ne font que des calculs au sein du pas de temps en cours de calcul.
Il a été décidé qu’OSRD utiliserait la méthode Runge-Kutta 4 parce qu’elle est légèrement plus précise que Euler-Cauchy et que c’est une méthode bien connue pour ce type de calcul, donc très adaptée à un simulateur open-source.
3 - Le système d'enveloppes
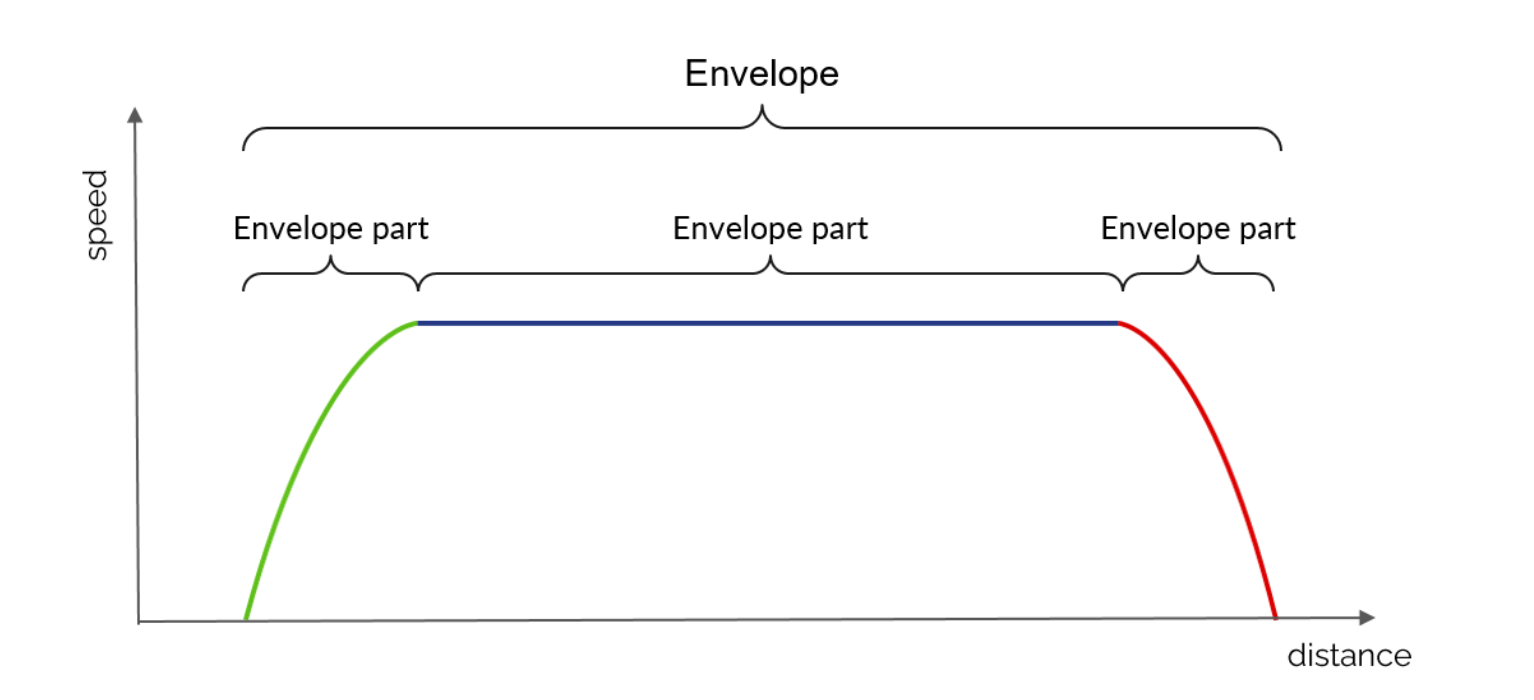
Le système d’enveloppes est une interface créée spécifiquement pour le calcul de marche d’OSRD. Il permet de manipuler différentes courbes espace/vitesse, de les découper, de les mettre bout à bout, d’interpoler des points spécifiques, et d’adresser beaucoup d’autres besoins nécessaires au calcul de marche.
Une interface spécifique dans le service OSRD Core
1 - EnvelopePart : courbe espace/vitesse, définie comme une séquence des points et possédant des métadonnées indiquant par exemple s’il s’agit d’une courbe d’accélération, de freinage, de maintien de vitesse, etc.
2 - Envelope : liste d’EnvelopeParts mises bout-à-bout et sur laquelle il est possible d’effectuer certaines opérations :
vérifier la continuité dans l’espace (obligatoire) et dans la vitesse (facultative)
chercher la vitesse minimale et/ou maximale de l’enveloppe
couper une partie de l’enveloppe entre deux points de l’espace
effectuer une interpolation de vitesse à une certaine position
calculer le temps écoulé entre deux positions de l’enveloppe
3 - Overlays : système permettant d’ajouter des EnvelopePart plus contraignantes (c’est-à-dire dont la vitesse est plus faible) à une enveloppe existante.
Enveloppes données vs enveloppes calculées
Pendant la simulation, le train est censé suivre certaines instructions de vitesse. Celles-ci sont modélisées dans OSRD par des enveloppes sous forme de courbes espace/vitesse. On en distingue deux types :
Les enveloppes provenant des données d’infrastructure et de matériel roulant, comme la vitesse maximale de la ligne et la vitesse maximale du train. Etant des données d’entrée de notre calcul, elles ne correspondent pas à des courbes ayant un sens physique, car elles ne sont pas issues des résultats d’une intégration réelle des équations physiques du mouvement.
Les enveloppes résultant d’une intégration réelle des équations du mouvement physique. Elles correspondent à une courbe physiquement tenable par le train et contiennent également des informations sur le temps.
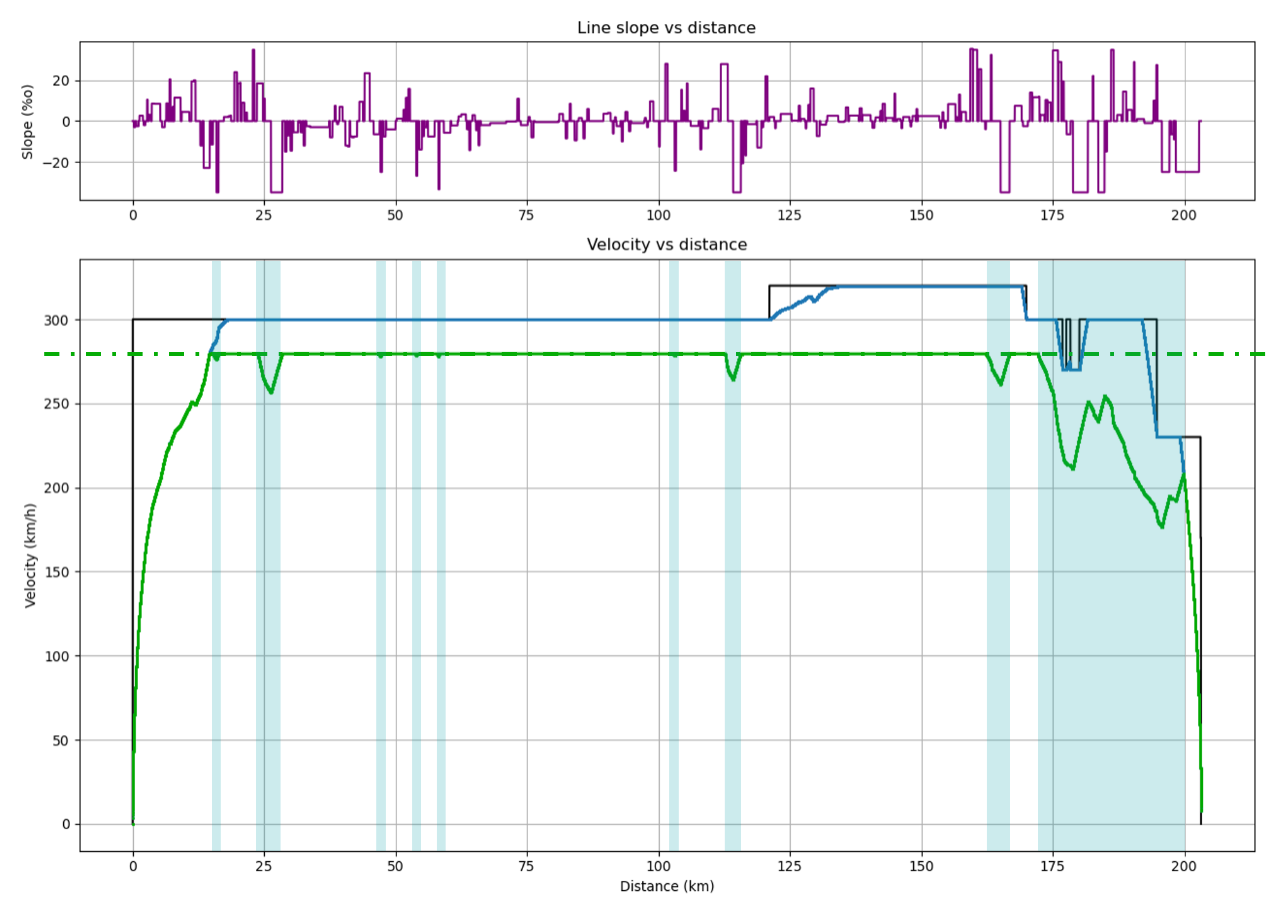
Un exemple simple pour illustrer cette différence : si l’on simule un trajet de TER sur une ligne de montagne, une des données d’entrée va être une enveloppe de vitesse maximale à 160km/h, correspondant à la vitesse maximale de notre TER. Mais cette enveloppe ne correspond pas à une réalité physique, car il se peut que sur certaines portions la rampe soit trop raide pour que le train arrive effectivement à maintenir cette vitesse maximale de 160km/h. L’enveloppe calculée présentera donc dans cet exemple un décrochage de vitesse dans les zones de fortes rampes, là où l’enveloppe donnée était parfaitement plate.
Simulation de plusieurs trains
Dans le cas de la simulation de nombreux trains, le système de signalisation doit assurer la sécurité. L’effet de la signalisation sur le calcul de marche d’un train est reproduit en superposant des enveloppes dynamiques à l’enveloppe statique. Une nouvelle enveloppe dynamique est introduite par exemple lorsqu’un signal se ferme. Le train suit l’enveloppe économique statique superposée aux enveloppes dynamiques, s’il y en a. Dans ce mode de simulation, un contrôle du temps est effectué par rapport à un temps théorique provenant de l’information temporelle de l’enveloppe économique statique. Si le train est en retard par rapport à l’heure prévue, il cesse de suivre l’enveloppe économique et essaie d’aller plus vite. Sa courbe espace/vitesse sera donc limitée par l’enveloppe d’effort maximum.
4 - Le processus de calcul de marche
Le calcul de marche dans OSRD est un processus à 4 étapes, utilisant chacune le système d’enveloppes :
Une première enveloppe est calculée au début de la simulation en regroupant toutes les limites de vitesse statiques :
vitesse maximale de la ligne
vitesse maximale du matériel roulant
limitations temporaires de vitesse (en cas de travaux sur une ligne par exemple)
limitations de vitesse par catégorie de train
limitations de vitesse selon la charge du train
limitations de vitesse correspondant à des panneaux de signalisation
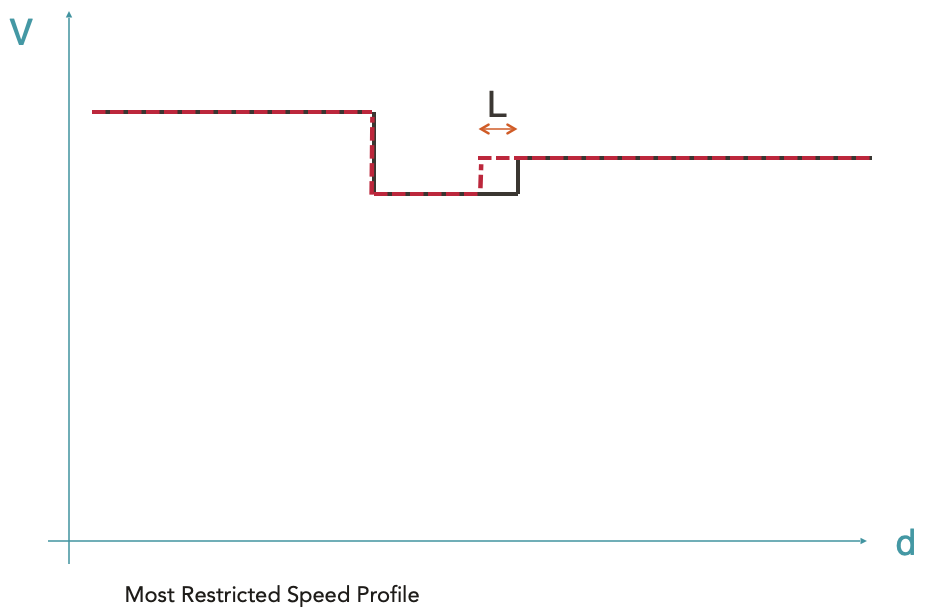
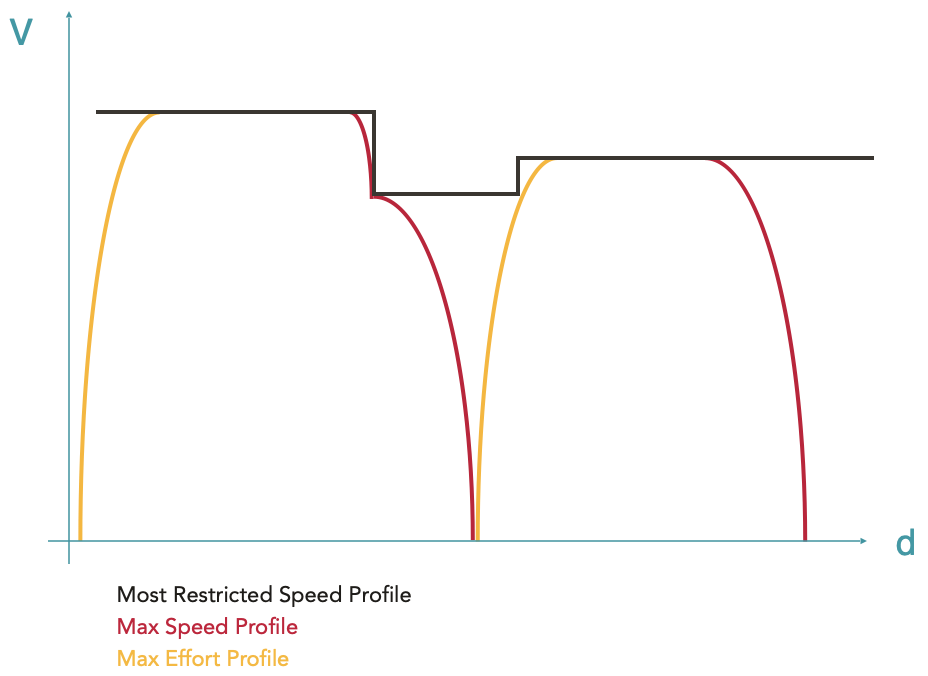
La longueur du train est également prise en compte pour s’assurer que le train n’accélère qu’une fois sa queue ayant quitté la zone de plus faible vitesse. Un décalage est alors appliqué à la courbe en pointillée rouge. L’enveloppe résultante (courbe noire) est appelée MRSP (Most Restricted Speed Profile) correspondant donc au profil de vitesse le plus restrictif. C’est sur cette enveloppe que seront calculées les étapes suivantes.
La ligne pointillée rouge représente la vitesse maximale autorisée en fonction de la position.
La ligne noire représente le MRSP où la longueur du train a été prise en compte.
Il est à noter que les différentes envelopeParts composant le MRSP sont des données d’entrée, elles ne correspondent donc pas à des courbes avec une réalité physique.
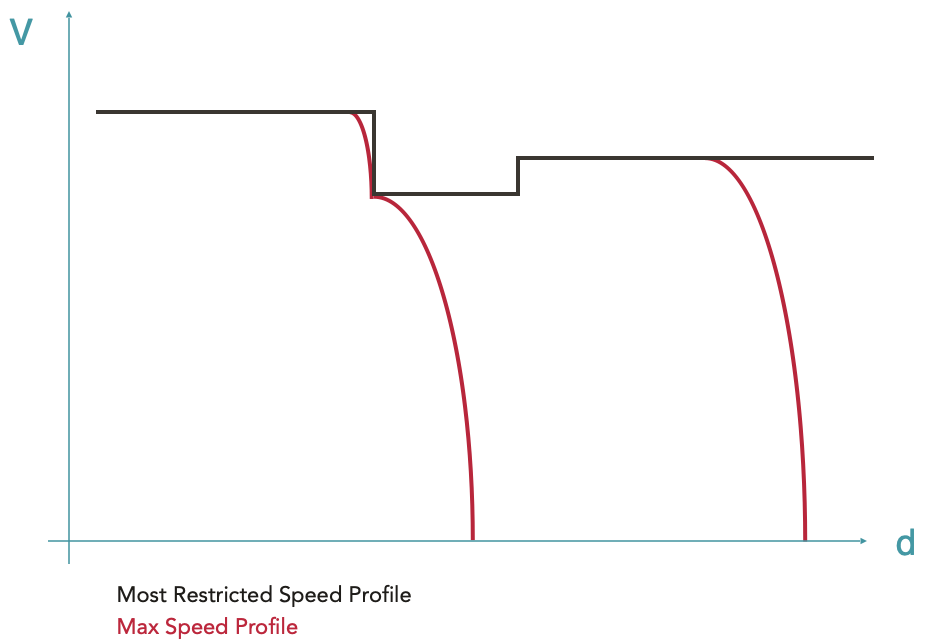
Calcul du profil de vitesse maximale
En partant du MRSP, toutes les courbes de freinage sont calculées grâce au système d’overlay (voir ici pour plus de détails sur les overlays), c’est-à-dire en créant des envelopeParts qui seront plus restrictives que le MRSP. La courbe ainsi obtenue est appelée Max Speed Profile (profil de vitesse maximale). Il s’agit de l’enveloppe de vitesse maximale du train, tenant compte de ses capacités de freinage.
Etant donné que les courbes de freinage ont un point de fin imposé et que l’équation de freinage n’a pas de solution analytique, il est impossible de prédire leur point de départ. Les courbes de freinage sont donc calculées à rebours en partant de leur point cible, c’est-à-dire le point dans l’espace où une certaine limite de vitesse est imposée (vitesse cible finie) ou le point d’arrêt (vitesse cible nulle).
Pour des raisons historiques en production horaire, les courbes de freinages sont calculées avec une décélération forfaitaire, dite décélération horaire (typiquement ~0,5m/s²) sans prendre en compte les autres forces. Cette méthode a donc également été implémentée dans OSRD, permettant ainsi de calculer les freinages de deux manières différentes : avec ce taux horaire ou avec une force de freinage qui vient simplement s’ajouter aux autres forces.
Calcul du profil d’effort maximal
Pour chaque point correspondant à une augmentation de vitesse dans le MRSP ou à la fin d’une courbe de freinage d’arrêt, une courbe d’accélération est calculée. Les courbes d’accélération sont calculées en tenant compte de toutes les forces actives (force de traction, résistance à l’avancement, poids) et ont donc un sens physique.
Pour les envelopeParts dont le sens physique n’a pas encore été vérifié (qui à ce stade sont les phases de circulation à vitesse constante, provenant toujours du MRSP), une nouvelle intégration des équations de mouvement est effectuée. Ce dernier calcul est nécessaire pour prendre en compte d’éventuels décrochages de vitesse dans le cas où le train serait physiquement incapable de tenir sa vitesse, typiquement en présence de fortes rampes (voir cet exemple).
L’enveloppe qui résulte de ces ajouts de courbes d’accélérations et de la vérification des plateaux de vitesse est appelée Max Effort Profile (profil d’effort maximal).
A ce stade, l’enveloppe obtenue est continue et a un sens physique du début à fin. Le train accélère au maximum, roule aussi vite que possible en fonction des différentes limites de vitesse et de ses capacités motrices, et freine au maximum. Le calcul de marche obtenu s’appelle la marche de base. Elle correspond au trajet le plus rapide possible pour le matériel roulant donné sur le parcours donné.
Application de marge(s)
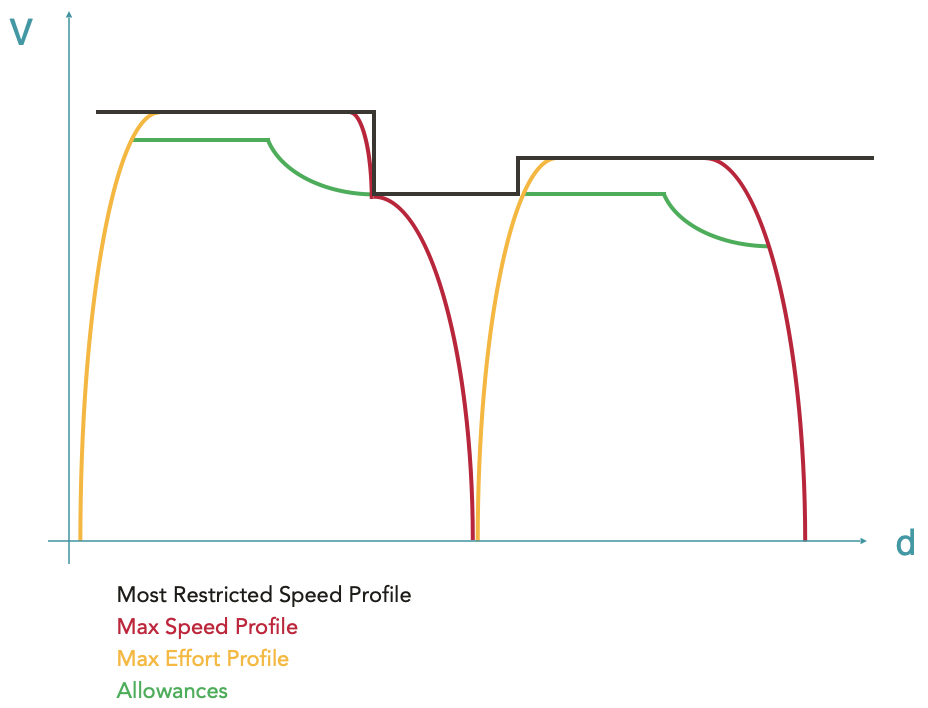
Après avoir effectué le calcul de la marche de base (correspondant au Max Effort Profile dans OSRD), il est possible d’y appliquer des marges (allowances). Les marges sont des ajouts de temps supplémentaire au parcours du train. Elles servent notamment à lui permettre de rattraper son retard si besoin ou à d’autres besoins opérationnels (plus de détails sur les marges ici).
Une nouvelle enveloppe Allowances est donc calculée grâce à des overlays pour distribuer la marge demandée par l’utilisateur sur l’enveloppe d’effort maximal calculée précédemment.
Dans le calcul de marche d’OSRD, il est possible de distribuer les marges d’une manière linéaire, en abaissant toutes les vitesses d’un certain facteur, ou économique, c’est-à-dire en minimisant la consommation d’énergie pendant le parcours du train.
5 - Les marges
La raison d’être des marges
Comme expliqué dans le calcul du Max Effort Profile, la marche de base représente la marche la plus tendue normalement réalisable, c’est-à-dire le trajet le plus rapide possible du matériel donné sur le parcours donné. Le train accélère au maximum, roule aussi vite que possible en fonction des différentes limites de vitesse et de ses capacités motrices, et freine au maximum.
Cette marche de base présente un inconvénient majeur : si un train part avec 10min de retard, il arrivera au mieux avec 10min de retard, car par définition il lui est impossible de rouler plus vite que la marche de base. Par conséquent, les trains sont programmés avec un ajout d’une ou de plusieurs marges. Les marges sont une détente du trajet du train, un ajout de temps à l’horaire prévu, qui se traduit inévitablement par un abaissement des vitesses de circulation.
Un train circulant en marche de base est incapable de rattraper son retard !
Le type de marge
On distingue deux types de marges :
La marge de régularité : il s’agit du temps complémentaire ajouté à la marche de base pour tenir compte de l’imprécision de la mesure de la vitesse, pour pallier les conséquences des incidents extérieurs venant perturber la marche théorique des trains, et pour maintenir la régularité de la circulation. La marge de régularité s’applique sur l’ensemble du trajet, bien que sa valeur puisse changer sur certains intervalles.
La marge de construction : il s’agit du temps ajouté / retiré sur un intervalle spécifique, en plus de la marge de régularité, mais cette fois pour des raisons opérationnelles (esquiver un autre train, libérer une voie plus rapidement, etc.)
Une marche de base à laquelle on vient ajouter une marge de régularité donne ce que l’on appelle une marche type.
La distribution de la marge
L’ajout de marge se traduisant par un abaissement des vitesses le long du trajet, plusieurs marches types sont possibles. En effet, il existe une infinité de solutions aboutissant au même temps de parcours.
En guise d’exemple simple, pour détendre la marche d’un train de 10% de son temps de parcours, il est possible de prolonger n’importe quel arrêt de l’équivalent en temps de ces 10%, tout comme il est possible de rouler à 1/1,1 = 90,9% des capacités du train sur l’ensemble du parcours, ou encore de rouler moins vite, mais seulement aux vitesses élevées…
Il y a pour l’instant deux algorithmes de distribution de la marge dans OSRD : linéaire et économique.
La distribution linéaire
La distribution de marge linéaire consiste simplement à abaisser les vitesses d’un même facteur sur la zone où l’utilisateur applique la marge. En voici un exemple d’application :
Cette distribution a pour avantage de répartir la marge de la même manière sur tout le trajet. Un train prenant du retard à 30% de son trajet disposera de 70% de sa marge pour les 70% de trajets restants.
La distribution économique
La distribution économique de la marge, présentée en détail dans ce document (MARECO est un algorithme conçu par la direction de la recherche SNCF), consiste à répartir la marge de la manière la plus économe possible en énergie. Elle est basée sur deux principes :
une vitesse plafond, évitant les vitesses les plus consommatrices en énergie
des zones de marche sur l’erre, situées avant les freinages et les fortes pentes, où le train circule à moteur coupé grâce à son inertie, permettant de ne consommer aucune énergie pendant ce laps de temps
Un exemple de marche économique. En haut, les pentes/rampes rencontrées par le train. Les zones de marche sur l’erre sont représentées en bleu.