Vous souhaitez utiliser OSRD, y contribuer, ou simplement en comprendre le fonctionnement ? Cette documentation est pour vous !
Version imprimable multipages. Cliquer ici pour imprimer.
Documentation
- 1: Explications
- 1.1: Architecture des conteneurs
- 1.2: Modèles
- 1.2.1: Catégories de matériels roulants
- 1.2.2: Exemple d'infrastructure
- 1.2.3: Zones neutres
- 1.3: Calcul de marche
- 1.3.1: Modélisation physique
- 1.3.2: Intégration numérique
- 1.3.3: Le système d'enveloppes
- 1.3.4: Le processus de calcul de marche
- 1.3.5: Les marges
- 1.4: Netzgrafik-Editor
- 2: Guides pratiques
- 2.1: Contribuer à OSRD
- 2.1.1: Avant toutes choses
- 2.1.2: Licence et mise en place
- 2.1.3: Contribuer au code
- 2.1.3.1: Principes généraux
- 2.1.3.2: Conventions back-end
- 2.1.3.3: Conventions front-end
- 2.1.3.4: Écrire du code
- 2.1.3.5: Conventions de commits
- 2.1.3.6: Partagez vos changements
- 2.1.3.7: Tests
- 2.1.4: Revue de code
- 2.1.5: Signaler des problèmes
- 2.1.6: Installer docker
- 2.1.7:
- 2.2: Déployer OSRD
- 2.2.1: Configuration de l'environnement de recherche STDCM
- 2.2.2: Docker Compose
- 2.2.3: Kubernetes avec Helm
- 2.3: Le design d'OSRD
- 2.4: Le logo
- 2.5: Publication
- 2.5.1: Processus de publication
- 2.5.2: Publier une nouvelle version
- 3: Référence technique
- 3.1: Architecture
- 3.1.1: Flux des données
- 3.1.2: Services
- 3.2: Documents de conception
- 3.2.1: Poste d'aiguillage
- 3.2.1.1: Éléments mobiles
- 3.2.1.2: Localisation
- 3.2.1.3: Reservation
- 3.2.1.4: Routage
- 3.2.1.5: Ordonnancement
- 3.2.1.6: Train
- 3.2.2: Signalisation
- 3.2.3: Détection de conflit
- 3.2.4: Calcul de marche v3
- 3.2.5: Recherche de sillons de dernière minute (STDCM)
- 3.2.5.1: Contexte métier
- 3.2.5.2: Module de recherche de sillons
- 3.2.5.2.1: Parcours de l'infrastructure
- 3.2.5.2.2: Détection de conflits
- 3.2.5.2.3: Représentation de l'espace de solutions
- 3.2.5.2.4: Discontinuités et retours en arrière
- 3.2.5.2.5: Contourner les conflits
- 3.2.5.2.6: Marge de régularité
- 3.2.5.2.7: Détails d'implémentation
- 3.2.6: Timetable v2
- 3.2.7: Authentification et autorisations
- 3.2.8: Gestion d'erreurs dans Editoast
- 3.2.9: Distribution asynchrone et adaptable des tâches entre composants
- 3.3: APIs
- 4: Wiki Ferroviaire
- 4.1: Glossaire
- 4.2: Signalisation
- 4.2.1: Les risques ferroviaires
- 4.2.2: Les signaux
- 4.2.3: Les régimes d’exploitation des lignes
- 4.2.3.1: Les lignes à une seule voie
- 4.2.3.1.1: La voie unique
- 4.2.3.1.2: La voie unique à signalisation simplifiée (VUSS)
- 4.2.3.1.3: La voie unique à trafic restreint (VUTR)
- 4.2.3.1.4: L’exploitation en navette
- 4.2.3.1.5: La voie banalisée
- 4.2.3.2: La double voie
- 4.2.3.2.1: Les installations de contresens (ICS)
- 4.2.3.2.2: La voie unique temporaire à caractère permanent (VUTP)
- 4.2.3.2.3: La voie unique temporaire (VUT)
- 4.2.3.2.4: Mouvement à contre-voie
- 4.2.4: Les systèmes d'espacement des trains
- 4.2.4.1: BA
- 4.2.4.2: ERTMS
- 4.2.4.3: Signalisation Ks
- 4.2.4.3.1: Linienförmige Zugbeeinflussung (LZB)
- 4.2.4.3.2: Punktförmige Zugbeeinflussung (PZB)
1 - Explications
Comprendre les concepts clés
Les explications abordent des thèmes et concepts clés d’un point de vue général et fournissent des informations et explications détaillées sur les éléments fondamentaux.
1.1 - Architecture des conteneurs
Comment les conteneurs fonctionnent ensemble et comment ils sont construits
Il y a 3 principaux conteneurs déployés dans une configuration OSRD standard :
- Gateway (inclut le frontend) : Sert le front-end, gère l’authentification et proxy les requêtes vers le backend.
- Editoast : Agit comme le backend qui interagit avec le front-end.
- Core : Gère les calculs et la logique métier, appelé par Editoast.
Déploiement standard
Le déploiement standard peut être représenté par le diagramme suivant.
flowchart TD
gw["gateway"]
front["fichiers statiques front-end"]
gw -- fichier local --> front
navigateur --> gw
gw -- HTTP --> editoast
editoast -- HTTP --> coreLes requêtes externes sont reçues par le gateway. Si le chemin demandé commence par /api, il sera transféré en utilisant HTTP vers editoast, sinon il servira un fichier avec le chemin demandé. Editoast atteint le core en utilisant HTTP si nécessaire.
Le gateway n’est pas seulement un proxy inverse avec le bundle front-end inclus, il fournit également tous les mécanismes d’authentification : utilisant OIDC ou des tokens.
1.2 - Modèles
Ce qui est modélisé dans OSRD, et comment c’est modélisé
1.2.1 - Catégories de matériels roulants
Définit les catégories de matériels roulants
Les catégories sont des regroupements de matériel roulant, soit par leurs caractéristiques, leurs performances ou par la nature des dessertes pour lesquelles ils ont été conçus ou sont utilisés.
Un même matériel roulant peut être utilisé pour différents types de circulation, et de desserte. Ce caractère versatile est contenu dans les attributs :
primary_category(requis) indique l’utilisation principale d’un matériel roulantother_categories(optionnel) indique les autres utilisations d’un matériel roulant
La catégorie principale d’un matériel roulant permet plusieurs fonctionnalités, comme le filtrage, un affichage différencié sur les graphiques ou réticulaire, et plus globalement, d’agréger des matériels roulants.
Catégories de matériels roulants
Les différentes catégories de matériel roulant disponibles par défaut sont les suivantes :
Train à grande vitesse(voir High-speed train)Train interurbain(voir Intercity train)Train régional(voir Regional train)Train suburbain(voir Commuter train)Train de fret(voir Freight train)Train de fret rapide(pareil que Train de fret, mais avec un code de composition différent,ME140au lieu deMA100par exemple)Train de nuit(voir Night train)Tram-train(voir Tram-train)Train touristique(voir Touristic train)Train de travaux(voir Work train)
Il est aussi prévu que, plus tard, un utilisateur puisse créer directement de nouvelles catégories de matériel roulant.
Matériels roulants réalistes open data
Afin de rendre l’application plus accessible aux utilisateurs en dehors de l’industrie ferroviaire, tels que des contributeurs externes et des laboratoires de recherche, et de préparer la sortie de la version publique “bac à sable” d’OSRD, plusieurs matériels roulants créés avec des données fictives sont disponibles pour tous les utilisateurs.
Ces matériels roulants ont été conçus pour couvrir la majorité des scénarios de simulation que les utilisateurs pourraient rencontrer.
Ces matériels roulants ne sont pas des matériels roulants existant réellement en raison de la confidentialité des données, mais ils s’en inspirent pour garantir le réalisme des simulations.
Ces matériels roulants sont fournis sous forme de fichiers JSON. Nous avons créé un matériel roulant représentatif de chaque catégorie présentée ci-dessus.
Les caractéristiques de ces matériels roulants ont été calculées à partir des valeurs moyennes des matériels roulants réels de chaque catégorie. De plus, la plupart de ces modèles ont été conçus pour être compatibles avec divers réseaux : ils sont principalement bi-modes (supportant plusieurs tensions et courants d’alimentation), ce qui n’est pas toujours le cas des matériels roulants réels.
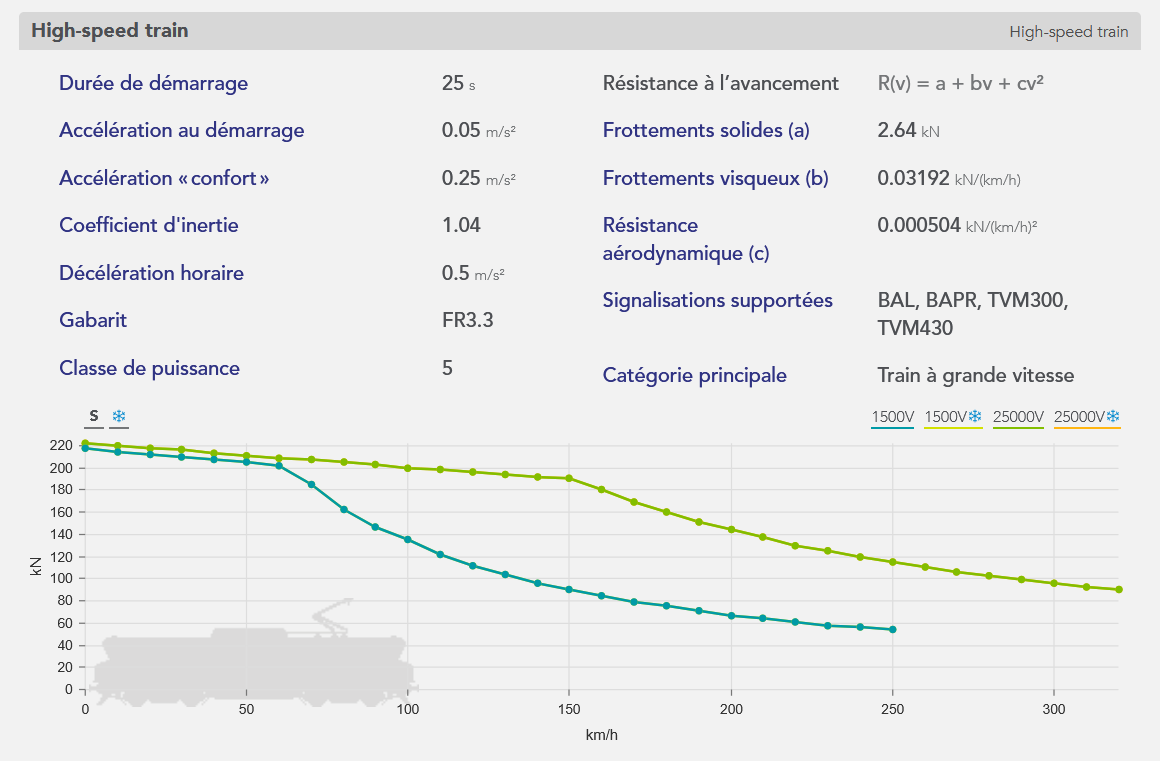
Un exemple de matériel roulant, un train à grande vitesse, est représenté ci-dessous, depuis l’éditeur de matériel roulant de l’application :
Open data
Puisque ces matériels roulants sont fictifs (mais réalistes), ils peuvent être librement utilisés dans des projets en dehors d’OSRD.
Pour y avoir accès et les utiliser dans l’application :
Depuis l’application open-source “bac à sable” : Les matériels roulants sont disponibles par défaut.
Depuis une application lancée localement : Utilisez la commande associée dans le README pour importer les matériels roulants de test dans votre base de données.
./scripts/load-railjson-rolling-stock.sh tests/data/rolling_stocks/realistic/*.json
1.2.2 - Exemple d'infrastructure
Explique par l’exemple comment les données d’infrastructure sont structurées
Introduction
Cette page donne un exemple de la manière dont les formats de données sont utilisés pour décrire une infrastructure dans OSRD.
À cette fin, prenons comme exemple l’infrastructure-jouet suivante :

Conseil
Pour zoomer sur un diagramme, cliquez sur le bouton d’édition qui apparaît au survol de celui-ci.Ce diagramme est un aperçu de l’infrastructure avec les lignes et les stations uniquement.
Cette infrastructure ne se veut pas réaliste, mais plutôt destinée à illustrer le modèle de données d’OSRD. Cet exemple sera créé étape par étape et expliqué en cours de route.
Le générateur d’infrastructures
Dans le dépôt OSRD se trouve une bibliothèque python conçue pour aider à générer des infrastructures dans un format compris par OSRD.
L’infrastructure discutée dans cette section peut être générée grâce au fichier small_infra.py. Pour en savoir plus sur les scripts de génération, vous pouvez consulter le README correspondant.
Voies
Sections de voie (Track Sections)
Les premiers objets que nous devons définir sont les TrackSections. La plupart des autres objets sont positionnés par rapport à celles-ci.
Une section de voie est une section de rail (sans aiguillages). On peut choisir de diviser les voies de son infrastructure en autant de sections qu’on le souhaite. Ici, nous avons choisi d’utiliser les sections de voie les plus longues possibles, ce qui signifie qu’entre deux aiguillages, il y a toujours une seule section de voie.
Les sections de voie sont ce sur quoi les trains simulés roulent. Ils sont l’équivalent abstrait des sections de rails physiques. Les sections de voie sont bidirectionnelles.
Dans cet exemple, nous définissons deux voies pour la ligne entre les stations Ouest et Nord-Est. Nous avons également des voies de contournement aux stations Nord et Centre-Ouest pour plus de réalisme. Enfin, nous avons trois voies distinctes dans la station Ouest, puisqu’il s’agit d’une plaque tournante majeure dans notre infrastructure imaginaire.

Important
Les TrackSections sont représentées par des flèches dans ce diagramme pour souligner le fait qu’elles ont un début et une fin. C’est important car les objets positionnés sur les sections de voie sont localisés en fonction de leur distance par rapport au début de leur section de voie.
Par conséquent, pour placer un objet au début de sa section de voie, définissez sa position à 0. Pour le déplacer à la fin de sa section de voie, définissez sa position à la length de la section de voie.
Ces attributs sont nécessaires pour que la section de voie soit complète :
length: la longueur de la section de voie en mètres.geo: les coordonnées dans la réalité (geo pour géographique), au format GeoJSON.- attributs cosmétiques :
line_name,track_name,track_numberqui sont utilisés pour indiquer le nom et les étiquettes qui ont été donnés aux voies / lignes dans la réalité.
Pour toutes les sections de voies de notre infrastructure, les attributs geo se rapprochent beaucoup au schéma donné.
Pour la plupart des sections de voies, leur length est proportionnelle à ce que l’on peut voir sur le diagramme. Pour préserver la lisibilité, des exceptions ont été faites pour TA6, TA7, TD0 et TD1 (qui font 10km et 25km).
Nœud
Un Node représente un nœud dans l’infrastructure. Dans une simulation OSRD, un train ne peut passer d’une section de voie à une autre que si elles sont reliées par un nœud.
Un nœud peut se présenter de deux manières différentes :
1) Aiguillages
Les aiguillages peuvent être vus comme une collection de liens de sections de voies, partitionnés en groupes. Chaque groupe représente un état de l’aiguillage. Passer d’un groupe à un autre peut prendre du temps, et au maximum un lien peut être prêt à être utilisé à la fois.
Dans le monde réel, les aiguillages ne sont pas uniques, mais plutôt des instances de modèles existants.
2) Liens de sections de voies
Pour le moment, nous n’avons créé que des sections de voies, qui ne sont pas interconnectées (les données géospatiales ne sont pas utilisées pour déduire quelles voies sont connectées).
Les link sont utilisés pour connecter deux sections de voie ensemble, tout comme un joint de soudure le ferait dans la vie réelle. Dans une simulation OSRD, un train ne peut passer d’une section de voie à une autre que si elles sont reliées par ce type de nœud, le link (ou par un autre NodeType).
Que ce soit pour les aiguillages ou les liens de sections de voies, les liens et les groupes ne font pas partie du switch lui-même, mais d’un objet NodeType, qui est partagé par les aiguillages du même modèle.
Types de Nœud
Les NodeTypes ont deux attributs obligatoires :
ports: Une liste de noms de ports. Un port est une extrémité du nœud qui peut être connecté à une section de voie.groups: Un table de correspondance entre le nom des groupes et les listes de branches (connexion entre 2 ports) qui caractérisent les différentes positions possibles du type de nœud
À tout moment, tous les nœuds ont un groupe actif, et peuvent avoir une branche active, qui appartient toujours au groupe actif. Pendant une simulation, le changement de branche active à l’intérieur d’un groupe est instantané, mais le changement de branche active entre les groupes prend un temps configurable.
Ceci est dû au fait qu’un Nœud peut-être un objet physique (dans le cas des aiguillages), et que le changement de branche active peut impliquer le déplacement de certaines de ses parties. Les groups sont conçus pour représenter les différentes positions qu’un Nœud peut avoir. Chaque groupe contient les liens qui peuvent être utilisés dans la position du Nœud associé.
Dans le cas des aiguilles, la durée nécessaire pour changer de groupe est stockée à l’intérieur du Nœud, car elle peut varier en fonction de l’implémentation physique du modèle d’aiguillage.
Nos exemples utilisent actuellement cinq NodeTypes. Il est possible d’ajouter un type de nœud si nécessaire via le champ extended_node_type.
1) Le lien entre deux sections de voies
Celui-ci représente le lien entre deux sections de voies. Il possède deux ports : A et B.

Il permet de créer un lien entre deux sections de voies tel que définis dans OSRD. Ce n’est pas un objet physique.
2) L’aiguille
L’omniprésent aiguillage en Y, qui peut être considéré comme la fusion de deux voies ou la séparation d’une voie.
Ce type d’aiguillage possède trois ports : A, B1 et B2.

Il y a deux groupes, chacun avec une connexion dans leur liste : A_B1, qui connecte A à B1, et A_B2 qui connecte A à B2.
Ainsi, à tout moment (sauf lorsque l’aiguille bouge pour changer de groupe), un train peut aller de A à B1 ou de A à B2 mais jamais aux deux en même temps. Un train ne peut pas aller de B1 à B2.
Une aiguille n’a que deux positions :
- A vers B1
- A vers B2


3) L’aiguillage de croisement
Il s’agit simplement de deux voies qui se croisent.
Ce type a quatre ports : A1, B1, A2 et B2.

Il ne comporte qu’un seul groupe contenant deux connexions : A1 vers B1 et A2 vers B2. En effet, ce type d’aiguillage est passif : il n’a pas de pièces mobiles. Bien qu’il n’ait qu’un seul groupe, il est tout de même utilisé par la simulation pour faire respecter les réservations de route.
Voici les deux connexions différentes que ce type d’aiguillage possède :
- A1 vers B1
- A2 vers B2


4) L’aiguillage de croisement double
Celui-ci ressemble plus à deux aiguilles dos à dos. Il possède quatre ports : A1, A2, B1 et B2.

Cependant, il comporte quatre groupes, chacun avec une connexion. Les quatre connexions possibles sont les suivantes :
- A1 vers B1
- A1 vers B2
- A2 vers B1
- A2 vers B2




5) L’aiguillage de croisement simple
Celui-ci ressemble plus à un mélange entre une aiguille simple et un croisement. Il possède quatre ports : A1, A2, B1 et B2.

Voici les trois connexions que peut réaliser cet aiguillage :
- A1 vers B1
- A1 vers B2
- A2 vers B2



Retour aux nœuds
Un Node possède trois attributs :
node_type: l’identifiantNodeTypede ce nœud.ports: une correspondance entre les noms de port et les extrémités des sections de voie.group_change_delay: le temps qu’il faut pour changer le groupe de l’aiguillage qui est actif.
Les noms des ports doivent correspondre aux ports du type du nœud choisi. Les extrémités de la section de voie peuvent être début ou fin, faites attention à choisir les bonnes.
La plupart des nœuds de notre exemple sont des nœuds habituels. Le chemin de la gare du Nord à la gare du Sud a deux aiguillages de croisement. Enfin, il y a un aiguillage de croisement double juste avant que la ligne principale ne se divise en lignes Nord-Est et Sud-Est.

Il est important de noter que ces nœuds sont présents par défaut dans le code du projet. Seuls les extended_switch_type ajoutés par l’utilisateur apparaîtront dans le railjson.
Courbes et pentes
Les Courbes et les Pentes sont essentielles pour des simulations réalistes. Ces objets sont définis comme une plage entre une position de début (begin) et de fin (end) sur une section de voie. Si une courbe / pente s’étend sur plus d’une section de voie, elle doit être ajoutée à toutes les sections.
Les valeurs des courbes / pentes sont constantes sur toute leur étendue. Pour des courbes / pentes variables, il faut créer plusieurs objets.
Les valeurs de pente sont mesurées en mètres par kilomètres, et les valeurs de courbe sont mesurées en mètres (le rayon de la courbe).
N’oubliez pas que la valeur
begin doit toujours être inférieure à la valeur end. C’est pourquoi les valeurs de courbe/pente peuvent être négatives : une pente ascendante de 1 allant du décalage 10 à 0 est identique à une pente descendante de -1 allant des décalages 0 à 10.Dans le fichier small_infra.py, nous avons des pentes sur les sections de voie TA6, TA7, TD0 et TD1.
Il y a également des courbes sur les sections de voie TE0, TE1, TE3 et TF1.
Enclenchement
Jusqu’à présent, tous les objets ont contribué à la topologie (forme) des voies. La topologie serait suffisante pour que les trains puissent naviguer sur le réseau, mais pas assez pour le faire en toute sécurité. pour assurer la sécurité, deux systèmes collaborent :
- L’enclenchement garantit que les trains sont autorisés à avancer
- La signalisation est le moyen par lequel l’enclenchement communique avec le train
Détecteurs
Ces objets sont utilisés pour créer des sections TVD (Track Vacancy Detection) : la zone de la voie située entre deux détecteurs est une section TVD. Lorsqu’un train rencontre un détecteur, la section dans laquelle il entre est occupée. La seule fonction des sections TVD est de localiser les trains.
Dans la réalité, les détecteurs peuvent être des compteurs d’essieux ou des circuits de voie par exemple.
Pour que cette méthode de localisation soit efficace, les détecteurs doivent être placés régulièrement le long de vos voies, pas trop nombreux pour des raisons de coût, mais pas trop peu, car les sections TVD seraient alors très grandes et les trains devraient être très éloignés les uns des autres pour être distingués, ce qui réduirait la capacité.
Il y a souvent des détecteurs à proximité de tous les extrémités des aiguillages. De cette façon, l’enclenchement est averti presque immédiatement lorsqu’un aiguillage est libéré, qui est alors libre d’être utilisé à nouveau.
Prenons l’exemple d’un aiguillage de croisement : si le train A le franchit du nord au sud et que le train B arrive pour le franchir de l’ouest à l’est, dès que le dernier wagon du train A a franchi l’aiguillage, B devrait pouvoir partir, puisque A se trouve maintenant sur une section de voie complètement indépendante.
Dans OSRD, les détecteurs sont des objets ponctuels. Les attributs dont ils ont besoin sont leur id et leur localisation sur la voie (track et offset).

Les carrés agglutinés représentent plusieurs détecteurs à la fois. En effet, certains tronçons de voie n’étant pas représentés sur toute leur longueur, nous n’avons pas pu représenter tous les détecteurs du tronçon de voie correspondant.
Quelques notes :
- Entre certains points, nous n’avons ajouté qu’un seul détecteur (et non pas deux), car ils étaient très proches les uns des autres, et cela n’aurait eu aucun sens de créer une minuscule section TVD entre eux. Cette situation s’est produite sur des sections de voies (TA3, TA4, TA5, TF0 et TG3).
- Dans notre infrastructure, il y a relativement peu de sections de voie qui sont assez longues pour nécessiter plus de détecteurs que ceux liés aux aiguillages. Ce sont, TA6, TA7, TDO, TD1, TF1, TG1 et TH1. Par exemple, TD0, qui mesure 25 km, compte en fait 17 détecteurs au total.
Butoirs (BufferStops)
Les BufferStops sont des obstacles destinés à empêcher les trains de dérailler en bout des voies.
Dans notre infrastructure, il y a un butoir sur chaque section de voie qui est un cul-de-sac. Il y a donc 8 butoirs au total.
Avec les détecteurs, ils définissent les limites des sections TVD (voir Détecteurs).
Itinéraires (Routes)
Une Route est un itinéraire dans l’infrastructure. Un sillon est une séquence de routes. Les itinéraires sont utilisés pour réserver des sections de sillon avec l’enclenchement. Voir la documentation dédiée.
Il est représenté avec les attributs suivants :
entry_pointetexit_point: Références de détecteurs ou de butées qui marquent le début et la fin de l’itinéraire.entry_point_direction: Direction à prendre sur la section de voie depuisentry_pointpour commencer l’itinéraire.switches_direction: Un ensemble de directions à suivre lorsqu’on rencontre un aiguillage sur notre itinéraire, de manière à reconstituer cet itinéraire deentry_pointjusqu’àexit_point.release_detectors: Lorsqu’un train franchit un détecteur de libération, les ressources réservées depuis le début de la route jusqu’à ce détecteur sont libérées.
Signalisation
Grâce à l’enclenchement, les trains sont localisés et autorisés à se déplacer. C’est un bon début, mais c’est inutile tant que les trains n’en sont pas informés. C’est là que les “signaux” entrent en jeu : les signaux réagissent aux enclenchements et peuvent être vus par les trains.
La façon dont les trains réagissent aux signaux dépend de l’aspect, du type de signal et du système de signalisation.
Voici les attributs les plus importants des signaux :
linked_detector: Le détecteur lié.type_code: Le type de signal.direction: La direction qu’il protège, qui peut être simplement interprétée comme la façon dont il peut être vu par un train entrant (puisqu’il n’y a des feux que d’un côté…). La direction est relative à l’orientation de la section de voie.- Des attributs cosmétiques comme
angle_geoandsidequi contrôlent la manière dont les signaux sont affichés dans le front-end.
Voici une visualisation de comment on peut représenter un signal, et quelle direction il protège.

La manière dont les signaux sont disposés dépend fortement du système de signalisation et du gestionnaire de l’infrastructure.
Voici les règles de base utilisées pour cet exemple d’infrastructure :
- Nous ajoutons deux signaux d’espacement (un par direction) pour chaque détecteur qui découpe une longue section de TVD en plus petites sections.
- Les entrées d’aiguillage où un train pourrait devoir s’arrêter sont protégées par un signal (qui est situé à l’extérieur de la section TVD de l’aiguillage). Il doit être visible depuis la direction utilisée pour approcher l’aiguillage. Lorsqu’il y a plusieurs aiguillages dans une rangée, seul le premier a généralement besoin d’être protégé, car l’enclenchement est généralement conçu pour ne pas encourager les trains à s’arrêter au milieu des intersections.
Notez que les détecteurs liés à au moins un signal ne sont pas représentés, car il n’y a pas de signaux sans détecteurs associés dans cet exemple.
Pour obtenir le id d’un détecteur lié à un signal, prenez le id du signal et remplacez S par D (par exemple SA0 -> DA0).

Sur TA6, TA7, TD0 et TD1 nous n’avons pas pu représenter tous les signaux car ces sections de voie sont très longues et comportent de nombreux détecteurs, donc de nombreux signaux.
Électrification
Pour permettre à des trains électriques de circuler sur notre infrastructure, nous devons spécifier les parties de celle-ci qui sont électrifiées.
Caténaires (Catenaries)
Les Catenaries représentent les câbles d’alimentation qui alimentent les trains électriques. Ils sont représentés avec les attributs suivants :
voltage: Une chaîne de caractères représentant le type d’alimentation électrique utilisée pour l’électrification.track_ranges: Une liste de portions de sections de voie (TrackRanges) couvertes par cette caténaire. UneTrackRangeest composée d’un identifiant de section de voie, d’une positionbeginet d’une positionend.
Dans notre exemple, nous avons deux Catenaries:
- Une avec
voltagedéfini sur"1500", qui couvre uniquement TA0. - Une avec
voltagedéfini sur"25000", qui couvre tous les autres sauf TD1.
Cela signifie que seuls les trains thermiques peuvent traverser la section de voie TD1.
Notre exemple montre également que, contrairement à son homologue réel, une seule Catenary peut couvrir toute l’infrastructure.
Sections Neutres (NeutralSections)
Dans certaines parties d’une infrastructure, les conducteurs de train sont sommés - principalement pour des raisons de sécurité - de couper l’alimentation électrique du train.
Pour représenter de telles parties, nous utilisons des NeutralSections. Elles sont représentées avec principalement les attributs suivants :
track_ranges: Une liste deDirectedTrackRanges(portions de sections de voie associées à une direction) couvertes par cette section neutre.lower_pantograph: Un booléen indiquant si le pantographe du train doit être abaissé pendant la traversée de cette section.
Dans notre exemple, nous avons trois NeutralSections : une à la jonction des caténaires "1500" et "25000", une sur TA6 et une sur TG1 et TG4.
Pour plus de détails sur le modèle, voir la page dédiée.
Divers
Points opérationnels (OperationalPoints)
Le point opérationnel est aussi connu sous le nom de Point Remarquable (PR).
Un OperationalPoint est une collection de points (OperationalPointParts) d’intérêt.
Par exemple, il peut être pratique (repère de conduite) de stocker l’emplacement des plateformes en tant que parties et de les regrouper par station dans des points opérationnels.
De la même manière, un pont au-dessus des voies sera un OperationalPoint, mais il comportera plusieurs OperationPointParts, une à l’intersection de chaque voie. Le champ local_track_name fournit un label lisible pour la voie dans le contexte d’un point opérationnel.
Dans l’exemple de l’infrastructure, nous n’avons utilisé que des points opérationnels pour représenter les stations. Les parties de points opérationnels sont représentées par des diamants violets. Gardez à l’esprit qu’un seul point opérationnel peut contenir plusieurs parties.

Limites de gabarit (Loading Gauge Limits)
Cet objet s’apparente aux Pentes et aux Courbes : il couvre une plage de section de voie, avec une position de début (begin) et de fin (end). Il représente une restriction sur les trains qui peuvent circuler sur la plage donnée, par poids ou par type de train (fret ou passagers).
Nous n’en avons pas mis dans nos exemples.
Sections de vitesse (SpeedSections)
Les SpeedSections représentent les limites de vitesse (en mètres par seconde) qui sont appliquées sur certaines parties des voies. Une SpeedSection peut s’étendre sur plusieurs sections de voie, et ne couvre pas nécessairement la totalité des sections de voie. Les sections de vitesse peuvent se chevaucher.
Dans notre exemple d’infrastructure, nous avons une section de vitesse couvrant l’ensemble de l’infrastructure, limitant la vitesse à 300 km/h. Sur une plus petite partie de l’infrastructure, nous avons appliqué des sections de vitesse plus restrictives.

1.2.3 - Zones neutres
Documentation des zones neutres et de leur implémentation
Objet physique que l’on cherche à modéliser
Introduction
Pour qu’un train puisse circuler, il faut soit qu’il ait une source d’énergie à bord (fuel, batterie, hydrogène, …) soit qu’on l’alimente en énergie tout au long de son parcours.
Pour fournir cette énergie, des câbles électriques sont suspendus au dessus des voies: les caténaires. Le train assure ensuite un contact avec ces câbles grâce à un patin conducteur monté sur un bras mécanique: le pantographe.
Zones neutres
Avec ce système il est difficile d’assurer l’alimentation électrique d’un train en continu sur toute la longueur d’une ligne: sur certaines portions de voie, il est nécessaire de couper l’alimentation électrique du train. Ce sont ces portions que l’on appelle zones neutres.
En effet, pour éviter les pertes énergétiques le long des caténaires, le courant est fourni par plusieurs sous-stations réparties le long des voies. Deux portions de caténaires alimentées par des sous-stations différentes doivent être isolées électriquement pour éviter les courts-circuits.
Par ailleurs, la façon dont les voies sont électrifiées (courant continu ou non par exemple) peut changer selon les us locaux et l’époque d’installation. Il faut également isoler électriquement les portions de voies qui sont électrifiées différemment. Le train doit aussi (sauf cas particuliers) changer de pantographe lorsqu’il change de type d’électrification.
Dans ces deux cas on indique alors au conducteur de couper la traction du train, et parfois même d’en baisser le pantographe.
Dans l’infrastructure française, ces zones sont signalées par des panneaux d’annonce, d’exécution et de fin. Ces panneaux portent par ailleurs l’indication de baisser le pantographe ou non. Les portions de voies entre l’exécution et la fin peuvent ne pas être électrifiées entièrement, et même ne pas posséder de caténaire (dans ce cas la zone nécessite forcément de baisser le pantographe).
Parfois, des pancartes REV (pour réversible) sont placées en aval des panneaux de fin de zone. Elles sont destinées aux trains qui circulent avec un pantographe à l’arrière du train. Ces pancartes indiquent que le conducteur peut reprendre la traction en toute sécurité.
Par ailleurs il peut parfois être impossible sur une courte portion de voie de placer une caténaire ou bien de lever le pantographe du train. Dans ce cas la ligne est tout de même considérée électrifiée, et la zone sans électrification (passage sous un pont par exemple) est considérée comme une zone neutre.
Matériel roulant
Après avoir traversé une zone neutre, un train doit reprendre la traction. Ce n’est pas immédiat (quelques secondes), et la durée nécessaire dépend du matériel roulant.
Il doit également, le cas échéant, relever son pantographe, ce qui prend également du temps (quelques dizaines de secondes) et dépend également du matériel roulant.
Ainsi la marche sur l’erre imposée au train s’étend en dehors de la zone neutre, puisque ces temps systèmes sont à décompter à partir de la fin de la zone neutre.
Modèle de données
Nous avons choisi de modéliser les zones neutres comme l’espace entre les panneaux liés à celle-ci (et non pas comme la zone précise où il n’y a pas de caténaire ou bien où la caténaire n’est pas électrifiée).
Cette zone est directionnelle, i.e. associée à un sens de circulation, pour pouvoir prendre en compte des placements de panneaux différents selon le sens. Le panneau d’exécution d’un sens donné n’est pas nécessairement placé à la même position que le panneau de fin de zone du sens opposé.
Pour une voie à double sens, une zone neutre est donc représentée par deux objets.
Le schema est le suivant
{
"lower_pantograph": boolean,
"track_ranges": [
{
"track": string,
"start": number,
"end": number,
"direction": enum
}
],
"announcement_track_ranges": [
{
"track": string,
"start": number,
"end": number,
"direction": enum
}
]
}
lower_pantograph: indique si le pantographe doit être baissé dans cette zonetrack_ranges: liste des portions de voie où le train ne doit pas tractionnerannouncement_track_ranges: liste des portions de voie entre le panneau d’annonce et le panneau d’exécution
Affichage
Cartographie
Les zones affichées dans la cartographie correspondent aux track_ranges, donc entre les panneaux d’exécution et de fin de zone. La couleur de la zone indique si le train doit baisser son pantographe dans la zone ou non.
La direction dans laquelle la zone s’applique n’est pas représentée.
Résultat de simulation
Dans l’affichage linéaire, c’est toujours la zone entre EXE et FIN qui est affichée.
Recherche d’itinéraire
Les zones neutres sont donc des portions de voie “non électrifiées” où un train électrique peut tout de même circuler (mais où il ne peut pas tractionner).
Lors de la recherche de chemin dans l’infrastructure, une portion de voie qui n’est pas couverte par les track_ranges d’un objet caténaire (documentation à écrire) peut être empruntée par un train électrique seulement si elle est couverte par les track_ranges d’une zone neutre.
Simulation
Dans la simulation, nous approximons le comportement du conducteur de la façon suivante :
- La marche sur l’erre est entamée dès que la tête du train passe le panneau d’annonce
- Le décompte des temps systèmes (relevé du pantographe et reprise de la traction) commence dès que la tête du train passe le panneau de fin.
Dans la simulation actuelle, il est plus facile de manier des bornes d’intégration spatiales que temporelles. Nous effectuons l’approximation suivante: lors de la sortie de la zone neutre, on multiplie les temps systèmes par la vitesse en sortie de zone. La marche sur l’erre est alors prolongée de la distance obtenue. Cette approximation est raisonnable car l’inertie du train et la quasi-absence de frottement garantissent que la vitesse varie peu sur cet intervalle de temps.
Potentielles améliorations
Plusieurs points pourraient être améliorés :
- On ne considère pas les pancartes REV, tous les trains ne possèdent donc qu’un pantographe à l’avant dans nos simulations.
- Les temps systèmes sont approximés.
- Le comportement conducteur est plutôt restrictif (la marche sur l’erre pourrait commencer après le panneau d’annonce).
- L’affichage des zones est limité: pas de représentation de la direction ou des zones d’annonce.
- Ces zones ne sont pas éditables.
1.3 - Calcul de marche
OSRD peut être utilisé pour effectuer deux types de calculs :
- Calcul de marche (standalone train simulation) : calcul du temps de parcours d’un train sur un trajet donné, effectué sans interaction entre le train et le système de signalisation.
- Simulation : calcul “dynamique” de plusieurs trains interagissant entre eux via le système de signalisation.
1 - Les données d’entrée
Un calcul de marche est basé sur 5 entrées :
- L’infrastructure : Topologie des lignes et des voies, position des gares et bâtiments voyageurs, position et type des aiguilles, signaux, vitesses maximales de ligne, profil de ligne corrigée (pentes, rampes et virages).
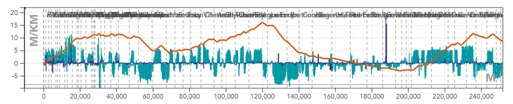
L’histogramme bleu est une représentation des déclivités en [‰] par position en [m]. Les déclivités sont positives pour les rampes et négatives pour les pentes.
La ligne orange représente le profil cumulé, c’est-à-dire l’altitude relative par rapport au point de départ.
La ligne bleue est une représentation des virages en termes de rayons des courbures en [m].
- Le matériel roulant : Dont les caractéristiques nécessaires pour effectuer la simulation sont représentées ci-dessous.

La courbe orange, appelée courbe effort-vitesse du matériel, représente l’effort moteur maximal en fonction de la vitesse de circulation.
La longueur, la masse, et la vitesse max du train sont représentées en bas de l’encadré.
L’horaire de départ permettant ensuite de calculer les horaires de passage aux différents points remarquables (dont gares).
Les marges : Temps ajouté au trajet du train pour détendre sa marche (voir page sur les marges).
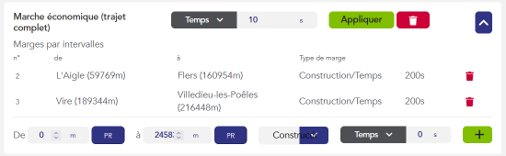
- Le pas de temps pour le calcul de l’intégration numérique.
2 - Les résultats
Les résultats d’un calcul de marche peuvent se représenter sous différentes formes :
- Le graphique espace/temps (GET) : représente le parcours des trains dans l’espace et dans le temps, sous la forme de traits globalement diagonaux dont la pente est la vitesse. Les arrêts apparaissent sous la forme de plateaux horizontaux.
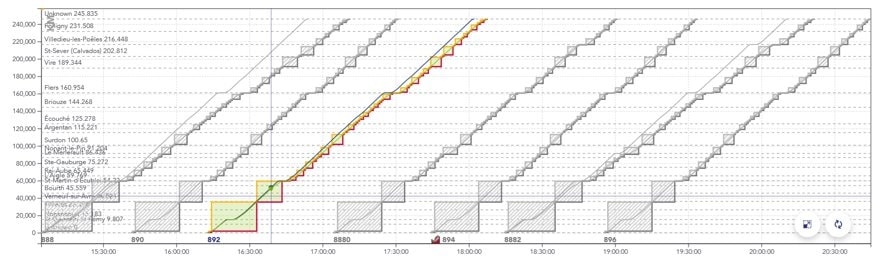
Exemple de GET avec plusieurs trains espacés d’environ 30mn.
L’axe x est l’horaire de passage du train, l’axe y est la position du train en [m].
La ligne bleue représente le calcul de marche le plus tendu pour le train, la ligne verte représente un calcul de marche détendu, dit « économique ».
Les rectangles pleins entourant les trajets représentent les portions de la voie successivement réservées au passage du train (appelées cantons).
- Le graphique espace/vitesse (GEV) : représente le parcours d’un seul train, cette fois-ci en termes de vitesse. Les arrêts apparaissent donc sous forme de décrochages de la courbe jusqu’à zéro, suivis d’un ré-accélération.

L’axe x est la position du train en [m], l’axe y est la vitesse du train en [km/h] .
La ligne violette représente la vitesse maximale autorisée.
La ligne bleue représente la vitesse dans le cas du calcul de marche le plus tendu.
La ligne verte représente la vitesse dans le cas du calcul de marche « économique ».
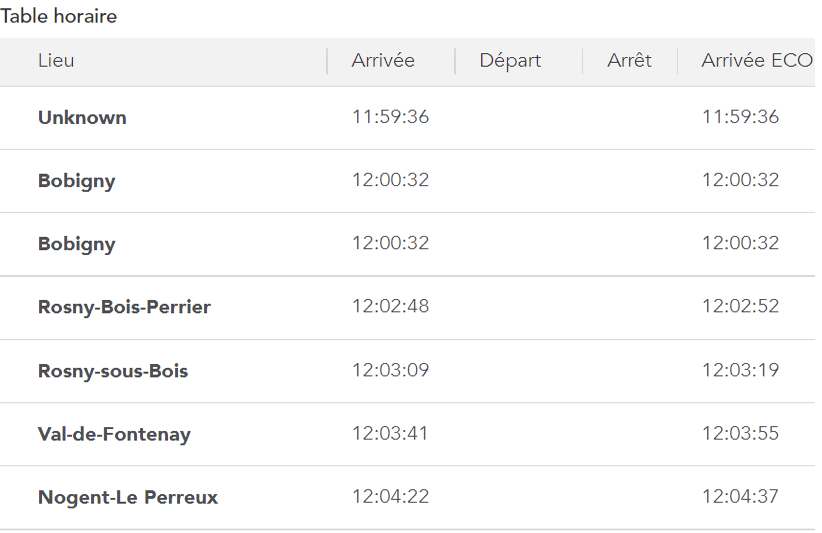
- Les horaires de passage du train aux différents points remarquables
1.3.1 - Modélisation physique
La modélisation physique joue un rôle important dans le cœur de calcul d’OSRD. C’est elle qui nous permet de simuler la circulation des trains, et elle doit être aussi réaliste que possible.
Bilan des forces
Pour calculer le déplacement du train au cours du temps, il faut d’abord calculer sa vitesse à chaque instant. Une manière simple d’obtenir cette vitesse est de passer par le calcul de l’accélération. Grâce au principe fondamental de la dynamique, l’accélération du train à chaque instant est directement dépendant des différentes forces qui lui sont appliquées : $$ \sum \vec{F}=m\vec{a} $$

Traction : La valeur de la force de traction \(F_{mot}\) dépend de plusieurs facteurs :
- du matériel roulant
- de la vitesse du train \(v^{\prime}x\), selon la courbe effort-vitesse ci-dessous :
$$ {\vec{F_{mot}}(v_{x^{\prime}}, x^{\prime})=F_{mot}(v_{x^{\prime}}, x^{\prime})\vec{e_x^{\prime}}} $$

L’axe x représente la vitesse du train en [km/h], l’axe y, la valeur de la force de traction en [kN].
- de l’action du conducteur, qui accélère plus ou moins fort en fonction de l’endroit où il se trouve sur son trajet
- Freinage : La valeur de la force de freinage \(F_{brk}\) dépend elle aussi du matériel roulant et de l’action du conducteur mais possède une valeur constante pour un matériel donné. Dans l’état actuel de la modélisation, le freinage est soit nul, soit à sa valeur maximale.
$$ \vec{F_{brk}}(x^{\prime})=-F_{brk}(x^{\prime}){\vec{e_{x^{\prime}}}} $$
Une seconde approche de la modélisation du freinage est l’approche dite horaire, car utilisée pour la production horaire à la SNCF. Dans ce cas, la décélération est fixe et le freinage ne dépend plus des différentes forces appliquées au train. Les valeurs de décélération typiques vont de 0.4 à 0.7m/s².
- Résistance à l’avancement : Pour modéliser la résistance à l’avancement du train on utilise la formule de Davis qui prend en compte tous les frottements et la résistance aérodynamique de l’air. La valeur de la résistance à l’avancement dépend de la vitesse \(v^{\prime}_x\). Les coefficients \(A\), \(B\), et \(C\) dépendent du matériel roulant.
$$ {\vec{R}(v_{x^{\prime}})}=-(A+Bv_{x^{\prime}}+{Cv_{x^{\prime}}}^2){\vec{e_{x^{\prime}}}} $$
- Poids (pentes + virages) : La force du poids donnée par le produit entre la masse \(m\) du train et la constante gravitationnelle \(g\) est projetée sur les axes \(\vec{e_x}^{\prime}\) et \(\vec{e_y}^{\prime}\).Pour la projection, on utilise l’angle \(i(x^{\prime})\), qui est calculé à partir de l’angle de déclivité \(s(x^{\prime})\) corrigé par un facteur qui prend en compte l’effet du rayon de virage \(r(x^{\prime})\).
$$ \vec{P(x^{\prime})}=-mg\vec{e_y}(x^{\prime})= -mg\Big[sin\big(i(x^{\prime})\big){\vec{e_{x^{\prime}}}(x^{\prime})}+cos\big(i(x^{\prime})\big){\vec{e_{{\prime}}}(x^{\prime})}\Big] $$
$$ i(x^{\prime})= s(x^{\prime})+\frac{800m}{r(x^{\prime})} $$
- Réaction du sol : La force de réaction du sol compense simplement la composante verticale du poids, mais n’a pas d’impact sur la dynamique du train car elle n’a aucune composante selon l’axe \({\vec{e_x}^{\prime}}\).
$$ \vec{R_{gnd}}=R_{gnd}{\vec{e_{y^{\prime}}}} $$
Equilibre des forces
L’équation du principe fondamental de la dynamique projetée sur l’axe \({\vec{e_x}^{\prime}}\) (dans le référentiel du train) donne l’équation scalaire suivante :
$$ a_{x^{\prime}}(t) = \frac{1}{m}\Big [F_{mot}(v_{x^{\prime}}, x^{\prime})-F_{brk}(x^{\prime})-(A+Bv_{x^{\prime}}+{Cv_{x^{\prime}}}^2)-mgsin(i(x^{\prime}))\Big] $$
Celle-ci est ensuite simplifiée en considérant que malgré la pente le train se déplace sur un plan et en amalgamant \(\vec{e_x}\) et \(\vec{e_x}^{\prime}\). La pente a toujours un impact sur le bilan des forces mais on considère que le train ne se déplace qu’horizontalement, ce qui donne l’équation simplifiée suivante :
$$ a_{x}(t) = \frac{1}{m}\Big[F_{mot}(v_{x}, x)-F_{brk}(x)-(A+Bv_{x}+{Cv_{x}}^2)-mgsin(i(x))\Big] $$
Résolution
La force motrice et la force de freinage dépendent de l’action du conducteur (il décide d’accélérer ou de freiner plus ou moins fort en fonction de la situation). Cette dépendance se traduit donc par une dépendance de ces deux forces à la position du train. La composante du poids dépend elle aussi de la position du train, car provenant directement des pentes et des virages situées sous ce dernier.
De plus, la force motrice dépend de la vitesse du train (selon la courbe effort vitesse) tout comme la résistance à l’avancement.
Ces différentes dépendances rendent impossible la résolution analytique de cette équation, et l’accélération du train à chaque instant doit être calculée par intégration numérique.
1.3.2 - Intégration numérique
Introduction
La modélisation physique ayant montré que l’accélération du train était influencée par différents facteurs variant le long du trajet (pente, courbure, force de traction du moteur…), le calcul doit passer par une méthode d’intégration numérique. Le trajet est alors séparé en étapes suffisamment courtes pour considérer tous ces facteurs comme constants, ce qui permet cette fois ci d’utiliser l’équation du mouvement pour calculer le déplacement et la vitesse du train.
La méthode d’intégration numérique d’Euler est la plus simple pour effectuer ce genre de calcul, mais elle présente un certain nombre d’inconvénients. Cet article explique la méthode d’Euler, pourquoi elle ne convient pas aux besoins d’OSRD et quelle méthode d’intégration doit être utilisée à la place.
La méthode d’Euler
La méthode d’Euler appliquée à l’intégration de l’équation du mouvement d’un train est :
$$v(t+dt) = a(v(t), x(t))dt + v(t)$$
$$x(t+dt) = \frac{1}{2}a(v(t), x(t))dt^2 + v(t)dt + x(t)$$

Les avantages de la méthode d’Euler
La méthode d’Euler a pour avantages d’être très simple à implémenter et d’avoir un calcul plutôt rapide pour un pas de temps donné, en comparaison avec d’autres méthodes d’intégration numérique (voir annexe)
Les inconvénients de la méthode d’Euler
La méthode d’intégration d’Euler présente un certain nombre de problèmes pour OSRD :
- Elle est relativement imprécise, et donc nécessite un faible pas de temps, ce qui génère beaucoup de données.
- En intégrant dans le temps, on ne connaît que les conditions du point de départ du pas d’intégration (pente, paramètres d’infrastructure, etc.) car on ne peut pas prédire précisément l’endroit où il se termine.
- On ne peut pas anticiper les futurs changements de directive : le train ne réagit qu’en comparant son état actuel à sa consigne au même instant. Pour illustrer c’est un peu comme si le conducteur était incapable de voir devant lui, alors que dans la réalité il anticipe en fonction des signaux, pentes, virages qu’il voit devant lui.
La méthode Runge-Kutta 4
La méthode Runge-Kutta 4 appliquée à l’intégration de l’équation du mouvement d’un train est :
$$v(t+dt) = v(t) + \frac{1}{6}(k_1 + 2k_2 + 2k_3 + k_4)dt$$
Avec :
$$k_1 = a(v(t), x(t))$$
$$k_2 = a\Big(v(t+k_1\frac{dt}{2}), x(t) + v(t)\frac{dt}{2} + k_1\frac{dt^2}{8}\Big)$$
$$k_3 = a\Big(v(t+k_2\frac{dt}{2}), x(t) + v(t)\frac{dt}{2} + k_2\frac{dt^2}{8}\Big)$$
$$k_4 = a\Big(v(t+k_3dt), x(t) + v(t)dt + k_3\frac{dt^2}{2}\Big)$$

Les avantages de la méthode de Runge Kutta 4
La méthode d’intégration de Runge Kutta 4 permet de répondre aux différents problèmes soulevés par celle d’Euler :
- Elle permet d’anticiper les changements de directive au sein d’un pas de calcul, représentant ainsi davantage la réalité de conduite d’un train.
- Elle est plus précise pour le même temps de calcul (voir annexe), permettant des étapes d’intégration plus grandes, donc moins de points de données.
Les inconvénients de la méthode de Runge Kutta 4
Le seul inconvénient notable de la méthode de Runge Kutta 4 rencontré pour l’instant est sa difficulté d’implémentation.
Le choix de la méthode d’intégration pour OSRD
Étude de la précision et de la vitesse de calcul
Différentes méthodes d’intégration auraient pu remplacer l’intégration d’Euler de base dans l’algorithme d’OSRD. Afin de décider quelle méthode conviendrait le mieux, une étude sur la précision et la vitesse de calcul de différentes méthodes a été menée. Cette étude sert à comparé les méthodes suivantes :
- Euler
- Euler-Cauchy
- Runge-Kutta 4
- Adams 2
- Adams 3
Toutes les explications sur ces méthodes peuvent être trouvées dans ce document, et le code python utilisé pour la simulation est ici.
La simulation calcule la position et la vitesse d’un TGV accélérant sur une ligne droite plate.
Simulations à pas de temps équivalent
Une courbe de référence a été simulée en utilisant la méthode d’Euler avec un pas de temps de 0,1s, puis le même parcours a été simulé en utilisant les autres méthodes avec un pas de temps de 1s. Il est alors possible de comparer simplement chaque courbe à la courbe de référence, en calculant la valeur absolue de la différence à chaque point calculé. Voici l’erreur absolue résultante de la position du train sur sa distance parcourue :

Il apparaît immédiatement que la méthode d’Euler est moins précise que les quatre autres d’environ un ordre de grandeur. Chaque courbe présente un pic où la précision est extrêmement élevée (erreur extrêmement faible), ce qui s’explique par le fait que toutes les courbes commencent légèrement au-dessus de la courbe de référence, la croisent en un point et finissent légèrement en dessous, ou vice versa.
Comme la précision n’est pas le seul indicateur important, le temps de calcul de chaque méthode a été mesuré. Voici ce que nous obtenons pour les mêmes paramètres d’entrée :
| Méthode d’intégration | Temps de calcul (s) |
|---|---|
| Euler | 1.86 |
| Euler-Cauchy | 3.80 |
| Runge-Kutta 4 | 7.01 |
| Adams 2 | 3.43 |
| Adams 3 | 5.27 |
Ainsi, Euler-Cauchy et Adams 2 sont environ deux fois plus lents que Euler, Adams 3 est environ trois fois plus lent, et RK4 est environ quatre fois plus lent. Ces résultats ont été vérifiés sur des simulations beaucoup plus longues, et les différents ratios sont maintenus.
Simulation à temps de calcul équivalent
Comme les temps de calcul de toutes les méthodes dépendent linéairement du pas de temps, il est relativement simple de comparer la précision pour un temps de calcul à peu près identique. En multipliant le pas de temps d’Euler-Cauchy et d’Adams 2 par 2, le pas de temps d’Adams 3 par 3, et le pas de temps de RK4 par 4, voici les courbes d’erreur absolue résultantes :

Et voici les temps de calcul :
| Méthode d’intégration | Temps de calcul (s) |
|---|---|
| Euler | 1.75 |
| Euler-Cauchy | 2.10 |
| Runge-Kutta 4 | 1.95 |
| Adams 2 | 1.91 |
| Adams 3 | 1.99 |
Après un certain temps, RK4 tend à être la méthode la plus précise, légèrement plus précise que Euler-Cauchy, et toujours bien plus précise que la méthode d’Euler.
Conclusions de l’étude
L’étude de la précision et de la vitesse de calcul présentée ci-dessus montre que RK4 et Euler-Cauchy seraient de bons candidats pour remplacer l’algorithme d’Euler dans OSRD : les deux sont rapides, précis, et pourraient remplacer la méthode d’Euler sans nécessiter de gros changements d’implémentation car ils ne font que des calculs au sein du pas de temps en cours de calcul. Il a été décidé qu’OSRD utiliserait la méthode Runge-Kutta 4 parce qu’elle est légèrement plus précise que Euler-Cauchy et que c’est une méthode bien connue pour ce type de calcul, donc très adaptée à un simulateur open-source.
1.3.3 - Le système d'enveloppes
Le système d’enveloppes est une interface créée spécifiquement pour le calcul de marche d’OSRD. Il permet de manipuler différentes courbes espace/vitesse, de les découper, de les mettre bout à bout, d’interpoler des points spécifiques, et d’adresser beaucoup d’autres besoins nécessaires au calcul de marche.
Une interface spécifique dans le service OSRD Core
Le système d’enveloppes fait partie du service core d’OSRD (voir l’architecture du logiciel).
Ses principaux composants sont :
1 - EnvelopePart : courbe espace/vitesse, définie comme une séquence des points et possédant des métadonnées indiquant par exemple s’il s’agit d’une courbe d’accélération, de freinage, de maintien de vitesse, etc.
2 - Envelope : liste d’EnvelopeParts mises bout-à-bout et sur laquelle il est possible d’effectuer certaines opérations :
- vérifier la continuité dans l’espace (obligatoire) et dans la vitesse (facultative)
- chercher la vitesse minimale et/ou maximale de l’enveloppe
- couper une partie de l’enveloppe entre deux points de l’espace
- effectuer une interpolation de vitesse à une certaine position
- calculer le temps écoulé entre deux positions de l’enveloppe

3 - Overlays : système permettant d’ajouter des EnvelopePart plus contraignantes (c’est-à-dire dont la vitesse est plus faible) à une enveloppe existante.
Enveloppes données vs enveloppes calculées
Pendant la simulation, le train est censé suivre certaines instructions de vitesse. Celles-ci sont modélisées dans OSRD par des enveloppes sous forme de courbes espace/vitesse. On en distingue deux types :
- Les enveloppes provenant des données d’infrastructure et de matériel roulant, comme la vitesse maximale de la ligne et la vitesse maximale du train. Etant des données d’entrée de notre calcul, elles ne correspondent pas à des courbes ayant un sens physique, car elles ne sont pas issues des résultats d’une intégration réelle des équations physiques du mouvement.
- Les enveloppes résultant d’une intégration réelle des équations du mouvement physique. Elles correspondent à une courbe physiquement tenable par le train et contiennent également des informations sur le temps.
Un exemple simple pour illustrer cette différence : si l’on simule un trajet de TER sur une ligne de montagne, une des données d’entrée va être une enveloppe de vitesse maximale à 160km/h, correspondant à la vitesse maximale de notre TER. Mais cette enveloppe ne correspond pas à une réalité physique, car il se peut que sur certaines portions la rampe soit trop raide pour que le train arrive effectivement à maintenir cette vitesse maximale de 160km/h. L’enveloppe calculée présentera donc dans cet exemple un décrochage de vitesse dans les zones de fortes rampes, là où l’enveloppe donnée était parfaitement plate.
Simulation de plusieurs trains
Dans le cas de la simulation de nombreux trains, le système de signalisation doit assurer la sécurité. L’effet de la signalisation sur le calcul de marche d’un train est reproduit en superposant des enveloppes dynamiques à l’enveloppe statique. Une nouvelle enveloppe dynamique est introduite par exemple lorsqu’un signal se ferme. Le train suit l’enveloppe économique statique superposée aux enveloppes dynamiques, s’il y en a. Dans ce mode de simulation, un contrôle du temps est effectué par rapport à un temps théorique provenant de l’information temporelle de l’enveloppe économique statique. Si le train est en retard par rapport à l’heure prévue, il cesse de suivre l’enveloppe économique et essaie d’aller plus vite. Sa courbe espace/vitesse sera donc limitée par l’enveloppe d’effort maximum.
1.3.4 - Le processus de calcul de marche
Le calcul de marche dans OSRD est un processus à 4 étapes, utilisant chacune le système d’enveloppes :
- Construction du profil de vitesse le plus restrictif
- Ajout des différentes courbes de freinage
- Ajout des différentes courbes d’accélération et vérification des courbes de vitesse constante
- Application de marge(s)
Calcul du profil de vitesse le plus restrictif
Une première enveloppe est calculée au début de la simulation en regroupant toutes les limites de vitesse statiques :
- vitesse maximale de la ligne
- vitesse maximale du matériel roulant
- limitations temporaires de vitesse (en cas de travaux sur une ligne par exemple)
- limitations de vitesse par catégorie de train
- limitations de vitesse selon la charge du train
- limitations de vitesse correspondant à des panneaux de signalisation
La longueur du train est également prise en compte pour s’assurer que le train n’accélère qu’une fois sa queue ayant quitté la zone de plus faible vitesse. Un décalage est alors appliqué à la courbe en pointillée rouge. L’enveloppe résultante (courbe noire) est appelée MRSP (Most Restricted Speed Profile) correspondant donc au profil de vitesse le plus restrictif. C’est sur cette enveloppe que seront calculées les étapes suivantes.

La ligne pointillée rouge représente la vitesse maximale autorisée en fonction de la position. La ligne noire représente le MRSP où la longueur du train a été prise en compte.
Il est à noter que les différentes envelopeParts composant le MRSP sont des données d’entrée, elles ne correspondent donc pas à des courbes avec une réalité physique.
Calcul du profil de vitesse maximale
En partant du MRSP, toutes les courbes de freinage sont calculées grâce au système d’overlay (voir ici pour plus de détails sur les overlays), c’est-à-dire en créant des envelopeParts qui seront plus restrictives que le MRSP. La courbe ainsi obtenue est appelée Max Speed Profile (profil de vitesse maximale). Il s’agit de l’enveloppe de vitesse maximale du train, tenant compte de ses capacités de freinage.
Etant donné que les courbes de freinage ont un point de fin imposé et que l’équation de freinage n’a pas de solution analytique, il est impossible de prédire leur point de départ. Les courbes de freinage sont donc calculées à rebours en partant de leur point cible, c’est-à-dire le point dans l’espace où une certaine limite de vitesse est imposée (vitesse cible finie) ou le point d’arrêt (vitesse cible nulle).

Pour des raisons historiques en production horaire, les courbes de freinages sont calculées avec une décélération forfaitaire, dite décélération horaire (typiquement ~0,5m/s²) sans prendre en compte les autres forces. Cette méthode a donc également été implémentée dans OSRD, permettant ainsi de calculer les freinages de deux manières différentes : avec ce taux horaire ou avec une force de freinage qui vient simplement s’ajouter aux autres forces.
Calcul du profil d’effort maximal
Pour chaque point correspondant à une augmentation de vitesse dans le MRSP ou à la fin d’une courbe de freinage d’arrêt, une courbe d’accélération est calculée. Les courbes d’accélération sont calculées en tenant compte de toutes les forces actives (force de traction, résistance à l’avancement, poids) et ont donc un sens physique.
Pour les envelopeParts dont le sens physique n’a pas encore été vérifié (qui à ce stade sont les phases de circulation à vitesse constante, provenant toujours du MRSP), une nouvelle intégration des équations de mouvement est effectuée. Ce dernier calcul est nécessaire pour prendre en compte d’éventuels décrochages de vitesse dans le cas où le train serait physiquement incapable de tenir sa vitesse, typiquement en présence de fortes rampes (voir cet exemple).
L’enveloppe qui résulte de ces ajouts de courbes d’accélérations et de la vérification des plateaux de vitesse est appelée Max Effort Profile (profil d’effort maximal).

A ce stade, l’enveloppe obtenue est continue et a un sens physique du début à fin. Le train accélère au maximum, roule aussi vite que possible en fonction des différentes limites de vitesse et de ses capacités motrices, et freine au maximum. Le calcul de marche obtenu s’appelle la marche de base. Elle correspond au trajet le plus rapide possible pour le matériel roulant donné sur le parcours donné.
Application de marge(s)
Après avoir effectué le calcul de la marche de base (correspondant au Max Effort Profile dans OSRD), il est possible d’y appliquer des marges (allowances). Les marges sont des ajouts de temps supplémentaire au parcours du train. Elles servent notamment à lui permettre de rattraper son retard si besoin ou à d’autres besoins opérationnels (plus de détails sur les marges ici).
Une nouvelle enveloppe Allowances est donc calculée grâce à des overlays pour distribuer la marge demandée par l’utilisateur sur l’enveloppe d’effort maximal calculée précédemment.

Dans le calcul de marche d’OSRD, il est possible de distribuer les marges d’une manière linéaire, en abaissant toutes les vitesses d’un certain facteur, ou économique, c’est-à-dire en minimisant la consommation d’énergie pendant le parcours du train.
1.3.5 - Les marges
La raison d’être des marges
Comme expliqué dans le calcul du Max Effort Profile, la marche de base représente la marche la plus tendue normalement réalisable, c’est-à-dire le trajet le plus rapide possible du matériel donné sur le parcours donné. Le train accélère au maximum, roule aussi vite que possible en fonction des différentes limites de vitesse et de ses capacités motrices, et freine au maximum.
Cette marche de base présente un inconvénient majeur : si un train part avec 10min de retard, il arrivera au mieux avec 10min de retard, car par définition il lui est impossible de rouler plus vite que la marche de base. Par conséquent, les trains sont programmés avec un ajout d’une ou de plusieurs marges. Les marges sont une détente du trajet du train, un ajout de temps à l’horaire prévu, qui se traduit inévitablement par un abaissement des vitesses de circulation.
Un train circulant en marche de base est incapable de rattraper son retard !
Le type de marge
On distingue deux types de marges :
- La marge de régularité : il s’agit du temps complémentaire ajouté à la marche de base pour tenir compte de l’imprécision de la mesure de la vitesse, pour pallier les conséquences des incidents extérieurs venant perturber la marche théorique des trains, et pour maintenir la régularité de la circulation. La marge de régularité s’applique sur l’ensemble du trajet, bien que sa valeur puisse changer sur certains intervalles.
- La marge de construction : il s’agit du temps ajouté / retiré sur un intervalle spécifique, en plus de la marge de régularité, mais cette fois pour des raisons opérationnelles (esquiver un autre train, libérer une voie plus rapidement, etc.)
Une marche de base à laquelle on vient ajouter une marge de régularité donne ce que l’on appelle une marche type.
La distribution de la marge
L’ajout de marge se traduisant par un abaissement des vitesses le long du trajet, plusieurs marches types sont possibles. En effet, il existe une infinité de solutions aboutissant au même temps de parcours.
En guise d’exemple simple, pour détendre la marche d’un train de 10% de son temps de parcours, il est possible de prolonger n’importe quel arrêt de l’équivalent en temps de ces 10%, tout comme il est possible de rouler à 1/1,1 = 90,9% des capacités du train sur l’ensemble du parcours, ou encore de rouler moins vite, mais seulement aux vitesses élevées…
Il y a pour l’instant deux algorithmes de distribution de la marge dans OSRD : linéaire et économique.
La distribution linéaire
La distribution de marge linéaire consiste simplement à abaisser les vitesses d’un même facteur sur la zone où l’utilisateur applique la marge. En voici un exemple d’application :

Cette distribution a pour avantage de répartir la marge de la même manière sur tout le trajet. Un train prenant du retard à 30% de son trajet disposera de 70% de sa marge pour les 70% de trajets restants.
La distribution économique
La distribution économique de la marge, présentée en détail dans ce document (MARECO est un algorithme conçu par la direction de la recherche SNCF), consiste à répartir la marge de la manière la plus économe possible en énergie. Elle est basée sur deux principes :
- une vitesse plafond, évitant les vitesses les plus consommatrices en énergie
- des zones de marche sur l’erre, situées avant les freinages et les fortes pentes, où le train circule à moteur coupé grâce à son inertie, permettant de ne consommer aucune énergie pendant ce laps de temps

Un exemple de marche économique. En haut, les pentes/rampes rencontrées par le train. Les zones de marche sur l’erre sont représentées en bleu.
1.4 - Netzgrafik-Editor
Logiciel open-source développé par SBB CFF FFS et son intégration dans OSRD
Netzgrafik-Editor (NGE) est un logiciel open-source qui permet la création, la modification et l’analyse d’horaires à intervalles réguliers, à un niveau de détail macroscopique, développé par les Chemins de Fer Fédéraux suisses (SBB CFF FFS). Voir les dépôts front-end et back-end.
OSRD et NGE sont sémantiquement différents: le premier fonctionne à un niveau de détail microscopique, est basé sur une infrastructure définie en qualité et représente une grille horaire composée d’instances uniques de trains, alors que le second fonctionne à un niveau de détail macroscopique, sans infrastructure explicite et représente un plan de transport composé de lignes de train cadencées. Cependant, ces différences, suffisamment proches, peuvent être manipulées pour fonctionner ensemble.
La compatibilité entre NGE et OSRD a été testée à travers une preuve de concept, en exécutant les deux applications comme services distincts sans synchronisation automatisée.
L’idée est de fournir à OSRD un outil graphique pour éditer (créer, mettre à jour et supprimer les horaires des trains) une grille horaire à partir d’un scénario d’étude opérationnelle, et obtenir en même temps des informations analytiques. Utiliser des niveaux de détail microscopique et macroscopique permet un second bénéfice : les calculs microscopiques d’OSRD étendent le périmètre de NGE, ses fonctionnalités et les informations fournies, comme par exemple les simulations microscopiques ou l’outil de détection de conflits.
L’objectif transversal de cette fonctionnalité est de faire collaborer deux projets open-source de deux grands gestionnaires d’infrastructure ferroviaire pour atteindre le même objectif, celui d’assurer une continuité numérique à différentes échelles temporelles pour les études d’exploitations ferroviaires.
1 - Intégration dans OSRD
OSRD a développé une version standalone de NGE, intégrée au code source, qui permet à NGE de fonctionner sans back-end. Ainsi, à des fins d’utilisation externe, un build de NGE standalone est disponible sur NPM, et est publié à chaque release. Enfin, pour répondre à des besoins spécifiques à OSRD, OSRD utilise un fork de NGE (dont le build, NGE standalone, est aussi disponible sur NPM), en restant le plus proche possible du répertoire officiel.
Malgré l’utilisation de frameworks JavaScript différents (ReactJS pour OSRD et Angular pour NGE), ce build permet à OSRD d’intégrer NGE au sein d’un iframe. Cet iframe instancie un Custom Element, qui est l’interface de communication entre les deux applications et démarre le build de NGE.
Une alternative pour répondre au problème d’intégration aurait été de réécrire NGE en web-components, pour les importer dans OSRD, mais cette solution a été abandonnée compte tenu de la quantité de travail que cela représenterait.
NGE, sous sa version standalone, communique avec OSRD à travers l’iframe grâce à des propriétés d’éléments du DOM :
@Input: avec la propriéténetzgrafikDto, déclenchée à la mise à jour du contenu du scénario depuis OSRD.@Output: avec la propriétéoperations, déclenchée à l’utilisation de NGE.
NGE est alors capable d’obtenir la grille horaire OSRD dès qu’un changement est effectué du côté d’OSRD, et OSRD est capable d’obtenir les modifications effectuées du côté de NGE.
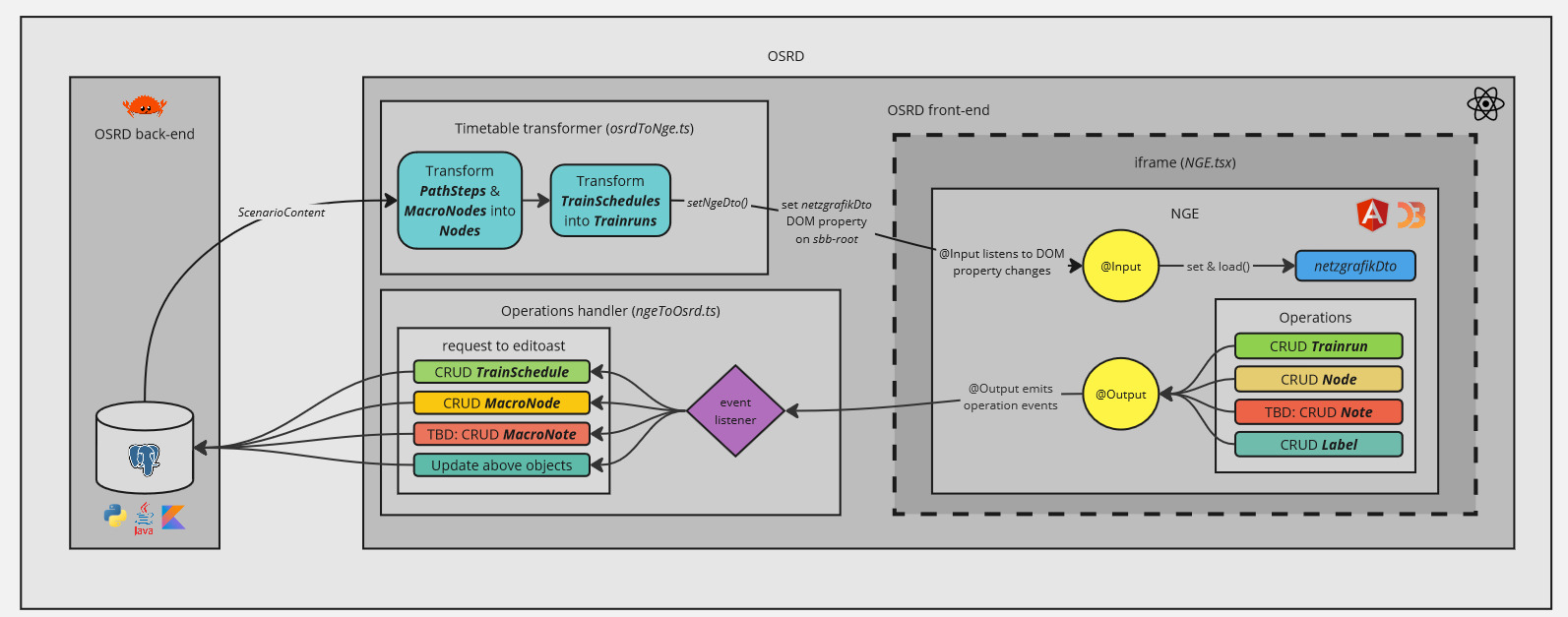
Il est important de noter que dans sa version standalone, NGE se repose alors ici sur le front-end d’OSRD, lui-même mis à jour par le back-end d’OSRD. De nouvelles tables en base de données, des modifications et de nouvelles routes sont alors nécessaires pour persister les informations macroscopiques d’un scénario.
2 - Convertisseurs
Pour surpasser les différences sémantiques et adapter les modèles de données, deux convertisseurs sont implémentés :
- [OSRD -> NGE] un convertisseur qui transforme une grille horaire OSRD en un modèle NGE. Les nœuds sont les points de passage décrits par les circulations, et dont les informations macroscopiques (position sur le réticulaire) sont stockés en base de données. Les circulations OSRD,
TrainSchedule, représentent alors des lignes de train cadencées dans NGE,Trainrun. Un concept de lignes de trains cadencées, sera bientôt implémenté pour permettre la convergence conceptuelle entre OSRD et NGE. - [OSRD <- NGE] un gestionnaire d’événements, qui transforme une action NGE en mise à jour de la base de données OSRD.
3 - Open-source (coopération / contribution)
Pour rendre NGE compatible avec OSRD, certaines modifications ont été demandées (désactivation du back-end, création de hooks sur les événements) et directement implémentées dans le répertoire officiel de NGE, avec l’accord et l’aide de l’équipe NGE.
Les contributions d’un projet à l’autre, de part et d’autre, sont précieuses et seront encouragées à l’avenir.
Cette fonctionnalité montre également que la coopération open-source est puissante et constitue un gain de temps considérable dans le développement de logiciels.
2 - Guides pratiques
Marches à suivre pour des tâches classiques
Les guides pratiques sont des marches à suivre. Vous êtes guidés pas-à-pas dans la résolution de problèmes, ou dans des scénarios classiques. Les connaissances requises sont plus élevées que pour les tutoriels, et le fonctionnement d’OSRD doit être compris.
2.1 - Contribuer à OSRD
Comment apporter sa pierre à l’édifice
2.1.1 - Avant toutes choses
Quelques premières informations importantes.
Déjà, merci de prendre le temps de contribuer !
Si les sections suivantes forment un guide du contributeur, ce n’est pas pour autant un ensemble de règles strictes. En fait, si vous avez déjà contribué à des gros projets open-source, la suite ne sera pas surprenante. Dans le cas contraire, elle vous sera probablement très utile !
Communiquer
Vous pouvez gagner du temps en discutant de votre projet de contribution avec les autres contributeurs :
- Créez une issue pour avoir un endroit pour discuter de votre contribution.
Se renseigner
Comme dans tout projet, chaque changement repose sur ce qui a été fait par le passé. Avant d’apporter un changement, renseignez-vous sur l’existant :
- Vous pouvez lire la documentation technique
- Il est préférable de lire le code source de l’application en rapport avec votre projet
- Vous pouvez contacter les derniers développeurs à avoir travaillé sur les zones du code en rapport avec votre projet
2.1.2 - Licence et mise en place
Comment mettre en place l’environnement de développement ? Qu’implique notre licence ?
La licence des contributions de code
Tout le code du dépôt OSRD est mis à disposition sous la licence LGPLv3. En contribuant du code, vous acceptez la redistribution de votre contribution sous cette license.
La licence LGPL interdit de modifier OSRD sans publier le code source de l’application modifiée : profitez du travail des autres, et laissez les autres profiter de votre travail !
Cette contrainte n’est pas contagieuse à travers les API : Il est possible d’utiliser OSRD comme bibliothèque, framework ou serveur pour s’interfacer avec des composants propriétaires. N’hésitez pas à proposer des changements pour répondre à vos besoins.
Mise en place
La plupart des développeurs OSRD utilisent Linux (y compris WSL). Vous pouvez utiliser Windows ou MacOS, mais pourriez rencontrer quelques problèmes.
Obtenir le code source
- Installer
git1 - Ouvrir un terminal2 dans le dossier qui contiendra le code source d’OSRD
git clone https://github.com/OpenRailAssociation/osrd.git
Lancer l’application
Docker est un outil qui réduit considérablement la préparation nécessaire pour travailler sur OSRD:
- télécharger le dernier build de développement :
docker compose pull - démarrer OSRD :
docker compose up - compiler et démarrer OSRD:
docker compose up --build - review une PR avec les images compilées par la CI:
TAG=pr-XXXXX docker compose up --no-build --pull always
Pour commencer :
- Installer
docker - Suivre le README d’OSRD.
2.1.3 - Contribuer au code
Apporter des modifications au code d’OSRD
Ce chapitre décrit le processus aboutissant à l’intégration de code au sein du projet. Si vous avez besoin d’aide, ouvrez une issue ou envoyez un message instantané.
L’application OSRD est divisée en plusieurs services écrits dans plusieurs langues. Nous essayons de suivre les bonnes pratiques générales en matière de code et de respecter les spécificités de chaque langage lorsque cela est nécessaire.
2.1.3.1 - Principes généraux
À lire en premier !
- Expliquez ce que vous faites et pourquoi.
- Documentez le nouveau code.
- Ajoutez des tests clairs et simples.
- Décomposez le travail en morceaux intelligibles.
- Prenez le temps de choisir de bons noms.
- Évitez les abréviations peu connues.
- Contrôle et cohérence de la réutilisation du code de tiers : une dépendance est ajoutée seulement si elle est absolument nécessaire.
- Chaque dépendance ajoutée diminue notre autonomie et notre cohérence.
- Nous essayons de limiter à un petit nombre les PRs de mise à jour des dépendances chaque semaine
dans chaque composant, donc regrouper les montées de version dans une même PR est une bonne option
(reportez-vous au
README.mdde chaque composant). - Ne pas réinventer la roue : en opposition au point précédent, ne réinventez pas tout à tout prix.
- S’il existe une dépendance dans l’écosystème qui est le standard « de facto », nous devrions fortement envisager de l’utiliser.
- Plus de code et de recommandations générales dans le dépôt principal CONTRIBUTING.md.
- Demandez toute l’aide dont vous avez besoin !
Consulter les conventions pour le back-end ‣
Consulter les conventions pour le front-end ‣
2.1.3.2 - Conventions back-end
Conventions de codes et bonnes pratiques pour le back-end
Python
Le code Python est utilisé pour certains paquets et pour les tests d’intégration.
- Suivez le Zen of Python.
- Les projets sont organisés avec uv
- Le code est linté avec ruff.
- Le code est formaté avec ruff.
- Les tests sont écrits avec pytest.
- Les types sont vérifiés avec pyright.
Rust
- Comme référence pour le développement de notre API, nous utilisons les Rust API guidelines. D’une manière générale, il convient de les respecter.
- Préférer les importations granulaires aux importations globales comme
diesel::*. - Les tests sont écrits avec le framework de base.
- Utilisez l’exemple de documentation pour savoir comment formuler et formater votre documentation.
- Utilisez un style de commentaire cohérent :
///les commentaires de la documentation sont au-dessus des invocations#[derive(Trait)].- Les commentaires
//doivent généralement être placés au-dessus de la ligne en question, plutôt qu’en ligne. - Les commentaires commencent par des lettres majuscules. Terminez-les par un point s’ils ressemblent à une phrase.
- Utilisez les commentaires pour organiser des portions de code longues et complexes qui ne peuvent être raisonnablement remaniées en fonctions distinctes.
- Le code est linté avec clippy.
- Le code est formaté avec fmt.
Java
- Le code est formaté avec checkstyle.
2.1.3.3 - Conventions front-end
Conventions de codes et bonnes pratiques pour le front-end
Nous utilisons ReactJS et tous les fichiers doivent être écrits en Typescript.
Le code est linté avec eslint, et formaté avec prettier.
Nomenclature

Les applications (osrd eex, osrd stdcm, éditeur infra, éditeur matériel) proposent des vues (gestion des projets, gestions des études, etc.) liées à des modules (projet, étude, etc.) qui contiennent les composants.
Ces vues sont constituées de composants et sous-composants tous issus des modules. En plus de contenir les fichiers de vues des applications, elles peuvent contenir un répertoire scripts qui propose des scripts liés à ces vues. Les vues déterminent la logique et l’accès au store.
Les modules sont des collections de composants rattachés à un objet (un scénario, un matériel roulant, un TrainSchedule). Ils contiennent :
- un répertoire components qui héberge tous les composants
- un répertoire styles optionnel par module pour le style des composants en scss
- un répertoire assets optionnel par module (qui contient les assets, de jeux de données par défaut par ex, spécifiques au module)
- un fichier reducers optionnel par module
- un fichier types optionnel par module
- un fichier consts optionnel par module
Un répertoire assets (qui contient les images et autre fichiers).
Enfin, un répertoire common qui propose :
- un répertoire utils pour les fonctions utilitaires communes à l’ensemble du projet
- un fichier types pour les types communs à l’ensemble du projet
- un fichier consts pour les constantes communes à l’ensemble du projet
Principes d’implémentation
Naming
On utilise en général les conventions suivantes dans le code:
- les composants et les types sont en PascalCase
- les variables sont en camelCase
- les clés de traduction sont en camelCase également
- les constantes sont en SCREAMING_SNAKE_CASE (sauf cas particulier)
- les classes css sont en kebab-case
Styles & SCSS
ATTENTION : en CSS/React, le scope d’une classe ne dépend pas de l’endroit où le fichier est importé mais est valide pour toute l’application. Si vous importez un fichier
scssau fin fond d’un composant (ce que nous déconseillons fortement par ailleurs), ses classes seront disponibles pour toute l’application et peuvent donc provoquer des effets de bord.
Il est donc très recommandé de pouvoir facilement suivre l’arborescence des applications, vues, modules et composants également au sein du code SCSS, et notamment imbriquer les noms de classes pour éviter les effets de bord.
Quelques conventions supplémentaires:
- toutes les tailles sont exprimées en px, sauf pour les polices que l’on exprime en rem.
- nous utilisons la bibliothèque classnames pour appliquer conditionnellement des classes : les classes sont séparées chacune dans un
stringet les opérations booléennes ou autres sont réalisées dans un objet qui retournera — ou pas — le nom de propriété comme nom de classe à utiliser dans le CSS.
Store/Redux
Le store permet de stocker des données qui seront accessibles à n’importe quel endroit de l’application. Il est découpé en slices, qui correspondent à nos applications.
Attention cependant à ce que notre store ne devienne pas un fourre-tout. L’ajout de nouvelles propriétés dans le store doit être justifié par le fait que la donnée en question est “haut-niveau” et devra être accessible depuis des endroits éloignés de la code base, et qu’une simple variable de state ou de contexte ne soit pas pertinent pour stocker cette information.
Pour plus de détails, nous vous invitons à consulter la documentation officielle.
Redux ToolKit (RTK)
Nous utilisons Redux ToolKit pour réaliser nos appels au backend.
RTK permet notamment de faire des appels à l’api et de mettre en cache les réponses. Pour plus de détails, nous vous invitons à consulter la documentation officielle.
Les endpoints et les types du backend sont générés directement à partir de l’open-api d’editoast et stockés dans generatedOsrdApi (avec la commande npm run generate-types). Ce fichier généré est ensuite enrichi par d’autres endpoints ou types dans osrdEditoastApi, qui peuvent être utilisés dans l’application.
A noter qu’il est possible de transformer des mutations en queries lors de la génération de generatedOsrdApi en modifiant le fichier openapi-editoast-config.
Lorsqu’un appel d’endpoint doit être skip parce qu’une variable n’est pas définie, on utilise skipToken de RTK pour éviter de devoir mettre des casts.
Traduction de l’application
La traduction de l’application est effectuée sur Weblate.
Imports
Il est recommandé d’utiliser le chemin complet pour chaque import, sauf si votre fichier à importer est dans le même répertoire.
ESLint est configuré pour trier automatiquement les imports en 4 groupes, séparés par une ligne vide et chacun trié alphabétiquement :
- React
- Librairies externes
- Fichiers internes en chemin absolu
- Fichiers internes en chemin relatif
Concernant l’import/export de types, ESLint et Typescript sont configurés de manière à ajouter automatiquement type devant un import de types, ce qui permet de:
- Améliorer les performances et le travail d’analyse du compilateur et du linter.
- Rendre ces déclarations plus lisibles, on voit clairement ce qu’on est en train d’importer.
- Alléger le bundle final (tous les types disparaissent à la compilation).
- Éviter des cycles de dépendances (ex: l’erreur disparaît avec le mot clé
type)

2.1.3.4 - Écrire du code
Apporter des modifications au code d’OSRD
Si vous n’être pas un habitué de Git, suivez ce tutoriel
Créez une branche
Si vous comptez contribuer régulièrement, vous pouvez demander accès au dépôt principal. Sinon, créez un fork.Ajoutez des changements sur votre branche
Essayez de découper votre travail en étapes macroscopiques, et sauvegardez vos changements dans un commit à la fin de chaque étape. Essayez de suivre les conventions du projet.Conservez votre branche à jour
git switch <your_branch> git fetch git rebase origin/dev
2.1.3.5 - Conventions de commits
Quelques bonnes pratiques et règles pour les messages de commits
Style de commits
Le format général des commits est le suivant :
composant1, composant2: description du changement à l'impératif
Description détaillée ou technique du contenu et de la motivation du
changement, si le titre n'est pas complètement évident.
- le message comme le code doit être en anglais (seulement des caractères ASCII pour le titre)
- il peut y avoir plusieurs composants, séparés par des
:quand il y a une relation hiérarchique, ou des,sinon - les composants sont en minuscule, avec éventuellement
-,_ou. - la description du changement à l’impératif commence par un verbe en minuscule
- le titre ne doit pas comporter de lien (
#est interdit)
Idéalement :
- le titre doit être autonome : pas besoin de lire autre chose pour le comprendre
- le titre du commit est entièrement en minuscule
- le titre est clair pour une personne étrangère au code
- le corps du commit contient une description du changement
Une vérification automatique est effectuée pour vérifier autant que possible ce formatage.
Contre-exemples de titres de commit
A éviter absolument:
component: update ./some/file.ext: préciser la mise à jour en question plutôt que le fichier, les fichiers sont des éléments techniques bienvenus dans le corps du commitcomponent: fix #42: préciser le problème corrigé, les liens (vers l’issue, etc.) sont encouragés dans le corps du commitwip: décrire le travail (et le finir)
Bienvenus pour faciliter la relecture, mais ne pas merger:
fixup! previous commit: un autosquash devra être lancé avant le mergeRevert "previous commit of the same PR": les deux commits devront être retirés avant merge
Le Developer Certificate of Origin (DCO)
Tous les projets d’OSRD utilisent le DCO (certificat du développeur d’origine) pour des raisons légales. Le DCO permet de confirmer que vous avez les droits sur le code que vous contribuez. Pour en savoir plus sur l’histoire et l’objectif du DCO, vous pouvez lire The Developer Certificate of Origin de Roscoe A. Bartlett.
Pour se conformer au DCO, tous les commits doivent inclure une ligne Signed-off-by.
Comment signer un commit avec Git dans un terminal ?
Pour signer un commit, il suffit d’ajouter l’option -s à votre commande git commit, comme ceci :
git commit -s -m "Your commit message"
Cela s’applique également lors de l’utilisation de la commande git revert.
Comment signer un commit avec Git dans Visual Studio Code (VS Code) ?
Allez dans Fichiers -> Préférences -> Paramètres, puis recherchez et
activez le paramètre Always Sign Off.
Ensuite, lorsque vous ferez un commit via l’interface de VS Code, ils seront automatiquement signés.
2.1.3.6 - Partagez vos changements
Comment soumettre votre code pour qu’il soit vérifié ?
L’auteur d’une pull request (PR) est responsable de son « cycle de vie ». Il se charge de contacter les différents acteurs, de suivre la revue de code, répondre aux commentaires et corriger le code suite à la revue de code (vous pouvez également consulter la page dédiée à la revue de code).
Ouvrez une pull request
Une fois que vos changements sont prêts, il est temps de proposer de les intégrer à la branchedev. Cela se fait dans l’interface web de Github.Si possible :
- Faites des PRs d’unités logiques et atomiques également (évitez de mélanger le refactoring, les nouvelles fonctionnalités et la correction de bugs en même temps).
- Ajoutez une description aux PR pour expliquer ce qu’elles font et pourquoi.
- Aidez le relecteur en suivant les conseils donnés dans l’article de mtlynch.
- Ajoutez les balises
area:<affected_area>pour montrer quelle partie de l’application a été impactée. Cela peut être fait via l’interface web.
Prenez en compte les retours
Une fois que votre PR est ouverte, d’autres contributeurs doivent donner leur avis sur votre proposition :- N’importe qui peut donner son avis.
- Il est nécessaire d’obtenir l’approbation d’un contributeur familier avec le code.
- Il est d’usage de prendre en compte tous les commentaires critiques.
- Les commentaires sont souvent écrits dans un style plutôt direct, dans le souci de collaborer efficacement vers une solution acceptable par tous.
- Une fois que tous les commentaires ont été pris en compte, un mainteneur intègre le changement.
Dans l’idéal, évitez les PR conséquentes et découpez le travail en plusieurs PR1 :
- facilite la relecture et peut aussi l’accélérer (plus facile de trouver 1 heure pour faire une relecture qu’une demi-journée),
- permet une approche plus agile avec des retours sur les premières itérations avant d’enchaîner sur la suite,
- garde un historique git plus simple à explorer (notamment lors d’un
git bisectà la recherche d’une regression par exemple).En cas d’impossibilité à éviter une PR conséquente, ne pas hésiter à solliciter plusieurs relecteurs qui pourront s’organiser, voire de faire la relecture ensemble, relecteurs et auteur.
Sur les PR conséquentes et vouées à évoluer dans le temps, conserver les corrections suite à la relecture dans des commits séparés facilite le travail de relecture. En cas de
rebaseet de relectures multiples par la même personne ils sont le moyen d’économiser une nouvelle relecture complète (demandez de l’aide au besoin) :
- Ajoutez des commits de fixup, amend, squash ou reword à l’aide de la documentation dédiée à git commit.
- Fusionnez automatiquement les corrections dans les commits originaux de votre PR et vérifier le résultat , à l’aide de
git rebase -i --autosquash origin/dev(juste avant le merge et une fois les relectures terminées).- Poussez vos changements avec
git push --force-with-leasecar vous ne poussez pas seulement de nouveaux commits, mais bien un changement des commits existants.
- N’hésitez pas à relancer vos interlocuteurs, plusieurs fois si besoin est : vous êtes responsable de la vie de votre pull request.
Cycle de review
Une revue de code est un processus itératif. Pour la fluidité d’une review, il est impératif de configurer correctement ses notifications github.
Il est conseillé de configurer les dépôts OSRD en “Participating and @mentions”. Cela permet d’être notifié d’activités uniquement sur les issues et PR auxquelles vous participez.
sequenceDiagram
actor A as Auteur PR
actor R as Reviewer/mainteneur
A->>R: Demande une review en notifiant spécifiquement quelques personnes
R->>A: Répond à la demande par oui ou non
loop Boucle entre auteur et reviewer
R-->>A: Commente, demande des changements
A-->>R: Répond à chaque commentaire/demande de changement
A-->>R: Corrige le code si nécessaire dans des « fixups » dédiés
R-->>A: Vérifie, teste, et commente à nouveau le code
R-->>A: Résout les conversations/demandes de changement le cas échéant
end
A->>R: Rebase si nécessaire
R->>A: Vérifie l'historique des commits
R->>A: Approuve la PR
Note right of A: Ajoute à la merge queueLes mainteneurs sont automatiquement notifiés par le système de
CODEOWNERS. L’auteur d’une PR est responsable de faire avancer sa PR dans le processus de review (quitte à notifier manuellement un mainteneur).
Continuer enfin vers les tests ‣
si vous n’êtes pas convaincus, cherchez “Stacked Diff” sur le web pour plus de détails sur le sujet, comme Stacked Diffs vs. Trunk Based Development (en) ↩︎
2.1.3.7 - Tests
Recommandations pour les tests
Back-end
- Les tests d’intégration sont écrits avec pytest dans le dossier
/tests. - Chaque route décrite dans les fichiers
openapi.yamldoit avoir un test d’intégration. - Le test doit vérifier à la fois le format et le contenu des réponses valides et invalides.
Front-end
L’écriture fonctionnelle des tests est réalisée avec les Product Owners, et les développeurs choisissent une implémentation technique qui répond précisément aux besoins exprimés et qui s’intègre dans les recommandations présentes ici.
Nous utilisons Playwright pour écrire les tests bout en bout, et vitest pour écrire les tests unitaires.
Les navigateurs testés sont pour l’instant Firefox et Chromium.
Principes de base
- Les tests doivent être courts (1min max) et aller droit au but.
- Les timeout arbitraires sont proscrits, un test doit systématiquement attendre un évènement spécifique. Il est possible d’utiliser le polling (retenter une action — un clic par exemple — au bout d’un certain temps) proposé dans l’API de Playwright.
- Les tests doivent tous pouvoir être parallélisables.
- Les tests ne doivent pas pointer/attendre des éléments de texte issus de la traduction, préférer l’arborescence du DOM ou encore placer des
idspécifiques. - On ne teste pas les données mais l’application et ses fonctionnalités. Des tests spécifiques aux données sont à élaborer par ailleurs.
Données
Les données testées doivent impérativement être des données publiques.
Les données nécessaires (infrastructure et matériel) aux tests sont proposées dans des fichiers json de l’application, injectées au début de chaque test et effacées à la fin peu importe son résultat ou la manière d’être stoppé, y compris par CTRL+C.
Cela se fait par des appels API en typescript avant de lancer le test à proprement parler.
Les données testées sont les mêmes en local ou via l’intégration continue.
Processus de développement des tests e2e
Les tests e2e sont implémentés de manière itérative, et livrés en même temps que les développements. À noter que:
- les tests e2e ne doivent être développés que sur les parcours utilisateurs critiques de l’application.
- ce workflow permet d’éviter les régressions immédiates après la sortie d’une fonctionnalité, de faire monter toute l’équipe en compétences sur les tests e2e et d’éviter des PRs très longues qui ajouteraient des tests e2e entiers
- on accepte que les tests e2e soient partiels le temps des développements et que le développement des tests alourdisse la taille des tickets et le temps de développement.
- certaines parties du test devront être mockées le temps que la fonctionnalité soit entièrement développée mais à la fin des développements, le test e2e devra être complet et les données mockées devront avoir disparu. Les modifications finales à faire dans le test pour retirer le mocking seront normalement minimes (uniquement changer les expected values).
- dans le cas de l’ajout d’une nouvelle fonctionnalité, il est préférable de séparer en des commits individuels l’implémentation de la nouvelle fonctionnalité et les tests afin de faciliter la review.
- les cas de test et les parcours utilisateur devront être définis en amont, au moment de la conception du ticket (refinement), avant le PIP. Ils pourront être proposés par un QA ou un.e PO, et devront être validés par un QA, le.la PO compétent.e et des devs front.
- si un test e2e touche à la configuration des tests e2e, à l’architecture du projet (typiquement le snapshotting) ou présente un risque de ralentir la CI, un atelier de conception (refinement) devra être organisé pour consulter les personnes en charge de l’architecture du projet et de la CI, notamment la team devops.
Atomicité d’un test
Chaque test doit être atomique : il se suffit à lui-même et ne peut pas être divisé.
Un test va cibler une fonctionnalité ou un composant, si ce dernier n’est pas trop gros. Un test ne testera pas tout un module ou tout une application, ce sera forcément un ensemble de tests afin de préserver l’atomicité des tests.
Si un test a besoin que des éléments soient créés ou ajoutés, ces opérations doivent être opérées par des appels API en typescript en amont du test, à l’instar de ce qui est fait pour l’ajout de données. Ces éléments doivent être supprimés à l’issue du test, peu importe son résultat ou la manière d’être stoppé, y compris par CTRL+C.
Cela permettra notamment la parallélisation des tests.
Un test peut cependant, dans certains cas de figure où cela est pertinent, contenir plusieurs sous-divisions de test, clairement explicitées, et justifiées (plusieurs test() dans un seul describe()).
Exemple de test
Le besoin : « nous voulons tester l’ajout d’un train dans une grille horaire ».
- ajouter l’infrastructure et le matériel roulant de test dans la base de données par appels API
- créer projet, étude et scénario avec choix de l’infra de test par appels API
- début du test qui clique sur « ajouter un ou plusieurs trains » jusqu’à la vérification de la présence des trains dans la grille horaire
- le test a réussi, a échoué, ou est stoppé, le projet, l’étude et le scénario sont effacés, ainsi que le matériel roulant et et l’infrastructure de test par appels API
NB : le test ne va pas tester toutes les possibilités offertes par l’ajout de trains, cela relève d’un test spécifique qui testerait la réponse de l’interface pour tous les cas de figure sans ajouter de trains.
2.1.4 - Revue de code
Comment faire des retours constructifs
Le reviewer/mainteneur s’engage à effectuer la revue de code rapidement, c’est aussi à lui qu’appartient de fermer les « request changes », de bien vérifier l’historique des commits, et de fusionner la « pull request » s’il en a les droits.
Nous vous soumettons quelques conseils et recommandations qui nous semblent pertinentes pour une revue de code humaine, pertinente et enrichissante pour tous ses contributeurs :
- How to Make Your Code Reviewer Fall in Love with You? par Michael Lynch.
- Si vous préférez l’audio, la présentation FOSDEM de Alya Abbott est aussi une bonne approche sur le sujet
- How to Do Code Reviews Like a Human? par Michael Lynch.
Cycle de review
Une revue de code est un processus itératif. Pour la fluidité d’une review, il est impératif de configurer correctement ses notifications github.
Il est conseillé de configurer les dépôts OSRD en “Participating and @mentions”. Cela permet d’être notifié d’activités uniquement sur les issues et PR auxquelles vous participez.
sequenceDiagram
actor A as Auteur PR
actor R as Reviewer/mainteneur
A->>R: Demande une review en notifiant spécifiquement quelques personnes
R->>A: Répond à la demande par oui ou non
loop Boucle entre auteur et reviewer
R-->>A: Commente, demande des changements
A-->>R: Répond à chaque commentaire/demande de changement
A-->>R: Corrige le code si nécessaire dans des « fixups » dédiés
R-->>A: Vérifie, teste, et commente à nouveau le code
R-->>A: Résout les conversations/demandes de changement le cas échéant
end
A->>R: Rebase si nécessaire
R->>A: Vérifie l'historique des commits
R->>A: Approuve la PR
Note right of A: Ajoute à la merge queueLes mainteneurs sont automatiquement notifiés par le système de
CODEOWNERS. L’auteur d’une PR est responsable de faire avancer sa PR dans le processus de review (quitte à notifier manuellement un mainteneur).
La pyramide de la revue de code

Script pour le test d’une PR
Lors de la revue d’une PR, il est utile de tester les changements en démarrant une instance de l’application OSRD basée sur la branche de la PR.
Un script est disponible pour lancer automatiquement une instance séparée et dédiée de l’application en utilisant le numéro de la PR. Le script utilise les images Docker déjà construites par la CI et lance l’application de manière isolée. Cela permet d’exécuter les deux instances en parallèle, sans conflits (idéal pour comparer les modifications, par exemple).
De plus, vous pouvez fournir une sauvegarde de la base de données, que le script chargera directement dans l’application.
L’application sera lancée sur le port 4001. Vous pouvez y accéder en suivant : http://localhost:4001/
Commandes Disponibles :
./scripts/pr-tests-compose.sh 8914 up: Télécharge les images CI générées pour la PR #8914 et lance l’application../scripts/pr-tests-compose.sh 8914 up-and-load-backup ./path_to_backup: Télécharge les images pour la PR #8914, restaure les données à partir de la sauvegarde spécifiée, et démarre l’application../scripts/pr-tests-compose.sh down: Arrête l’instance de test de l’application pour la PR #8914../scripts/pr-tests-compose.sh down-and-clean: Arrête l’instance de test et nettoie l’ensemble des volumes docker de l’instance (base de donnée PG, cache Valkey, RabbitMQ) pour éviter tout effet de bord.
Accès aux Services :
À l’exception du serveur frontend, tous les services sont disponibles sur localhost, avec un léger ajustement de port (pour éviter les conflits avec l’environnement de développement) : pour la liste des ports, reportez-vous au fichier docker compose dédié.
2.1.5 - Signaler des problèmes
Comment signaler un bug ou suggérer une amélioration
N’hésitez pas à signaler tout ce qui vous semble important !
Notre outil de suivi des bugs est github. Il est nécessaire de s’inscrire pour signaler un bug.
Suivez ce lien et choisissez le modèle qui correspond à votre cas de figure.
Bugs
- Le bug doit avoir une description correcte et le modèle du bug doit être rempli avec soin.
- Le bug doit être étiqueté avec (pour les membres de l’équipe) :
kind:bug- une ou plusieurs
area:<affected_area>si possible (si la zone affectée n’est pas connue, laissez-la vide et elle sera ajoutée plus tard par un autre membre de l’équipe). - un
severity:<bug_severity>si possible (si la sévérité n’est pas connue, laissez-la vide et elle sera ajoutée plus tard par un autre membre de l’équipe).severity:minor: L’utilisateur peut encore utiliser la fonctionnalité.severity:major: L’utilisateur ne peut parfois pas utiliser la fonctionnalité.severity:critical: L’utilisateur ne peut pas utiliser la fonctionnalité.
- Les membres de l’équipe OSRD peuvent modifier les étiquettes des problèmes (gravité, domaine, type, …). Vous pouvez laisser un commentaire pour expliquer les changements.
- Si vous travaillez sur un bug ou planifiez de travailler sur un bug, assignez vous au bug.
- Les PRs qui résolvent des bugs doivent ajouter des tests de régression pour s’assurer que le bug ne reviendra pas dans le futur.
2.1.6 - Installer docker
Peu importe votre système d’exploitation, docker requiert linux pour fonctionner. Lorsqu’utilisé sous un autre système d’exploitation, docker a besoin de machines virtuelles linux pour build et exécuter des images.
Il y a deux types d’installation docker :
- docker engine est l’application en ligne de commande
- docker desktop est une application graphique, qui gère aussi la virtualisation
Voici nos suggestions :
- Si vous êtes sous linux, installez docker engine via votre gestionnaire de packet
- Si vous êtes sous MacOS / Windows, installez docker desktop si vous y êtes autorisés
- Si vous êtes sous windows, et voulez faire fonctionner docker sous WSL, ou ne pouvez pas utiliser docker desktop, suivez le guide docker sous WSL
- Si vous êtes sous MacOS, et vous ne pouvez pas utiliser docker desktop, suivez le guide colima pour MacOS
Docker sous WSL
Cette option d’installation est très utile, car elle permet de disposer d’une installation tout à fait normale de docker engine Linux à l’intérieur de WSL, qui reste accessible depuis Windows.
- Installez WSL (Si vous avez une vieille version de WSL, lancez
wsl --upgrade) - Obtenez une image WSL depuis le store microsoft (par exemple, debian or ubuntu)
- Activez le support systemd depuis la VM WSL
- Suivez le tutoriel d’installation docker engine pour votre distribution WSL
- Si vous avez docker desktop installé, vous pouvez le configurer pour qu’il utilise WSL
MacOS colima
Cette procédure permet d’installer docker sans passer par docker desktop. Elle utilise colima comme solution de virtualisation.
- Installez homebrew
brew install docker docker-compose colima- Installez le plugin compose :
mkdir -p ~/.docker/cli-plugins && ln -sfn $(brew --prefix)/opt/docker-compose/bin/docker-compose ~/.docker/cli-plugins/docker-compose - Configurez colima :
- pour des macbooks apple silicon (M1/M2) :
colima start --cpu 2 --memory 6 --arch aarch64 --vm-type=vz --vz-rosetta --mount-type=virtiofs - pour de petites infrastructures:
colima start --cpu 2 --memory 4 - pour de grosses infrastructures:
colima start --cpu 2 --memory 6
brew services start colimapour lancer automatiquement colima au démarrage- Quittez votre terminal, ouvrez-en un nouveau
- Vous pouvez maintenant utiliser docker CLI
Si vous utiliser rancher desktop, veuillez soit:
- désinstaller l’application
- sélectionner
ManueldansPréférences>Application>Environnement
En cas d’erreur au démarrage avec Rosetta 2, lancez
colima delete et réessayez (le format de disque n’est pas compatible). Les paramètres seront perdus.Si vous avez cette erreur: error getting credentials - err: exec: "docker-credential-osxkeychain": executable file not found in $PATH
Ouvrez ~/.docker/config.json, et enlevez "credsStore": "osxkeychain"
2.1.7 -
Cycle de review
Une revue de code est un processus itératif. Pour la fluidité d’une review, il est impératif de configurer correctement ses notifications github.
Il est conseillé de configurer les dépôts OSRD en “Participating and @mentions”. Cela permet d’être notifié d’activités uniquement sur les issues et PR auxquelles vous participez.
sequenceDiagram
actor A as Auteur PR
actor R as Reviewer/mainteneur
A->>R: Demande une review en notifiant spécifiquement quelques personnes
R->>A: Répond à la demande par oui ou non
loop Boucle entre auteur et reviewer
R-->>A: Commente, demande des changements
A-->>R: Répond à chaque commentaire/demande de changement
A-->>R: Corrige le code si nécessaire dans des « fixups » dédiés
R-->>A: Vérifie, teste, et commente à nouveau le code
R-->>A: Résout les conversations/demandes de changement le cas échéant
end
A->>R: Rebase si nécessaire
R->>A: Vérifie l'historique des commits
R->>A: Approuve la PR
Note right of A: Ajoute à la merge queueLes mainteneurs sont automatiquement notifiés par le système de
CODEOWNERS. L’auteur d’une PR est responsable de faire avancer sa PR dans le processus de review (quitte à notifier manuellement un mainteneur).
2.2 - Déployer OSRD
Apprenez à déployer OSRD dans différents environnements
Tout d’abord, nous recommandons de se familiariser sur l’architecture des conteneurs d’OSRD.
Nous allons couvrir comment déployer OSRD dans les configurations suivantes :
- Utiliser docker compose sur un seul nœud.
- Utiliser helm sur un cluster kubernetes.
Il est également possible de déployer manuellement chaque service d’OSRD sur un système, mais nous ne couvrirons pas ce sujet dans ce guide.
NB
Pour que l’outil STDCM fonctionne, il faut configurer l’environnement de recherche STDCM, une configuration stockée en base de données. Consultez la page dédiée pour plus d’informations.2.2.1 - Configuration de l'environnement de recherche STDCM
Comment configurer l’environnement de recherche STDCM
Pour que l’outil STDCM fonctionne, il faut configurer l’environnement de recherche STDCM, une configuration stockée en base de données.
Les champs configurables sont les suivants :
pub struct StdcmSearchEnvironment {
pub infra_id: i64,
pub electrical_profile_set_id: Option<i64>,
pub work_schedule_group_id: Option<i64>,
pub timetable_id: i64,
pub search_window_begin: NaiveDateTime,
pub search_window_end: NaiveDateTime,
}
Cette configuration est récupérée par le frontend afin que les bons objets et bornes temporelles soient utilisés de manière transparente par l’utilisateur.
Pour configurer cette environnement, vous pouvez soit :
- Utiliser l’API REST prévue à cet effet (voir l’openAPI d’editoast dans la section stdcm_search_environment)
- Utiliser le CLI editoast (exécutez
editoast stdcm-search-env helppour plus d’informations)
2.2.2 - Docker Compose
Utiliser docker compose pour un déploiement sur un seul nœud
Le projet OSRD inclut un fichier docker-compose.yml conçu pour faciliter le déploiement d’un environnement OSRD pleinement fonctionnel. Exclusivement destiné à des fins de développement, cette configuration Docker Compose pourrait être adaptée pour des déploiements rapides sur un seul nœud.
Avertissement
Cette configuration est prévue seulement à des fins de développement. Par exemple, aucune authentification n’est prise en charge et le front-end est déployé en mode développement (reconstruit à la volée). Si vous souhaitez déployer une version d’OSRD dédiée à un environment de production, veuillez suivre le déploiement via KubernetesPrérequis
Avant de procéder au déploiement, assurez-vous que vous avez installé :
- Docker
- Docker Compose
Vue d’ensemble de la configuration
Le fichier docker-compose.yml définit les services suivants :
- PostgreSQL : Une base de données PostgreSQL avec l’extension PostGIS.
- Valkey : Un serveur Valkey pour le cache.
- Core : Le service central OSRD.
- Front : Le service front-end pour OSRD.
- Editoast : Un service OSRD responsable de diverses fonctions d’édition.
- Gateway : Sert de passerelle pour les services OSRD.
- Wait-Healthy : Un service utilitaire pour s’assurer que tous les services sont sains avant de procéder.
Chaque service est configuré avec des contrôles de santé, des montages de volumes et les variables d’environnement nécessaires.
Étapes du déploiement
- Cloner le dépôt : Tout d’abord, clonez le dépôt OSRD sur votre machine locale.
- Configuration : La configuration par défaut nécessite le renseignement d’une variable d’environnement pour le service Editoast: ROOT_URL.
Il faut lui donner la valeur de l’URL qui pointe vers le service Editoast par la gateway. Par exemple “http://your-domain.com/api".
Vous pouvez également ajuster d’autres variables d’environnement si nécessaire.
Si vous utilisez un proxy d’entreprise il est important de renseigner les variables
http_proxyetno_proxy- Pour le build:
http_proxy - Pour osrdyne et editoast
no_proxy="osrd-*" - Pour openfga
no_proxy="0.0.0.0,::1"
- Pour le build:
- Construire et exécuter : Naviguez vers le répertoire contenant
docker-compose.ymlet exécutez :
docker-compose up --build
Cette commande construit les images et démarre les services définis dans le fichier Docker Compose.
Accès aux services
Bien que tous les services HTTP soient utilisés via la passerelle (http://localhost:4000), vous pouvez accéder directement à chaque service en utilisant leurs ports exposés :
- PostgreSQL : Accessible sur
localhost:5432. - Valkey : Accessible sur
localhost:6379. - Service Core : Accessible sur
localhost:8080. - Front-End : Accessible sur
localhost:3000. - Editoast : Accessible sur
localhost:8090.
Notes et considérations
- Cette configuration est conçue pour le développement et les déploiements rapides. Pour les environnements de production, des considérations supplémentaires en matière de sécurité, de scalabilité et de fiabilité doivent être abordées.
- Assurez-vous que le
POSTGRES_PASSWORDet d’autres identifiants sensibles sont gérés en toute sécurité, en particulier dans les déploiements de production.
2.2.3 - Kubernetes avec Helm
Utilisation de Helm pour les déploiements Kubernetes
La Helm Chart du projet OSRD fournit une solution pour déployer les services OSRD dans un environnement Kubernetes de manière standardisée. Ce document décrit les options de configuration disponibles dans le Helm Chart.
Prérequis
Avant de procéder au déploiement, assurez-vous que vous avez installé :
- Un cluster Kubernetes opérationnel
- Une base de données PostgreSQL avec les extensions PostGIS, unaccent et pg_trgm installées
- Un serveur Valkey (utilisé pour le cache)
- Un server Rabbitmq (utilisé pour l’échange de messages)
Stateful editoast
Editoast est un service quasiment capable d’être mis à l’échelle horizontalement (stateless). Cependant, une partie de l’application nécessite un stockage en RAM cohérent et donc ne supporte pas la mise à l’échelle. Cette petite partie est appelée editoast stateful.
Le Helm Chart déploie deux service OSRD:
- Le premier
editoast(stateless) qui utilise un Horizontal Pod Autoscaler (hpa). - Le deuxième
stateful-editoastqui n’à qu’une seule réplique pour assurer la cohérence des données en RAM.
Vous pouvez visualiser le déploiement recommandé ici :
flowchart TD
gw["gateway"]
front["fichier statiques front-end"]
gw -- fichier local --> front
navigateur --> gw
gw -- HTTP --> stateful-editoast
gw -- HTTP --> editoast-1
gw -- HTTP --> editoast-2
gw -- HTTP --> editoast-N
stateful-editoast -- AMQP --> RabbitMQ
editoast-1 -- AMQP --> RabbitMQ
editoast-2 -- AMQP --> RabbitMQ
editoast-N -- AMQP --> RabbitMQ
RabbitMQ -- AMQP --> Core-X
Osrdyne -- HTTP/AMQP --> RabbitMQ
Osrdyne -- Control --> Core-XConfiguration de la Helm Chart (values)
Le Helm Chart est configurable à travers les valeurs suivantes :
Editoast
editoast: Configuration pour le service Editoast.init: Configuration d’initialisation.replicaCount: Nombre de réplicas, permettant la mise à l’échelle horizontale.hpa: Configuration de l’Horizontal Pod Autoscaler.- Autres options standard de déploiement Kubernetes.
Stateful Editoast
stateful-editoast: Service Editoast spécialisé dans les requêtes/infra/{infra_id}image: Image Docker à utiliser (généralement la même que Editoast).- Autres options standard de déploiement Kubernetes.
Osrdyne
osrdyne: Service osrdyne qui permet de contrôler les cores.image: Image Docker à utiliser.amqp: Connection au rabbitMQ- Autres options standard de déploiement Kubernetes.
Gateway
gateway: Configuration pour le gateway OSRD.- Comprend des options de service, d’ingress et d’autres options de déploiement Kubernetes.
config: Configurations spécifiques pour l’authentification et les proxys de confiance.
Déploiement
Le chart est disponible dans le dépôt OCI ghcr. Vous pouvez trouver 2 versions de la chart :
- Charts stables :
oci://ghcr.io/openrailassociation/osrd-charts/osrd - Charts de développement :
oci://ghcr.io/openrailassociation/osrd-charts/osrd-dev
Pour déployer les services OSRD en utilisant Helm :
Configurer les valeurs : Ajustez les valeurs selon vos besoins de déploiement.
Installer le Chart : Utilisez la commande
helm installpour installer la chart dans votre cluster Kubernetes.helm install osrd oci://ghcr.io/openrailassociation/osrd-charts/osrd -f values.yml
2.3 - Le design d'OSRD
Les couleurs, la police, les usages…
Tout est présenté dans un site dédié https://design.osrd.fr
Un « design system » est en cours d’élaboration.

2.4 - Le logo
Le logo d’OSRD, ses variantes, et son usage
Vous pouvez télécharger chaque logo indépendamment en cliquant directement dessus, ou tous les logos compressés dans un fichier zip.
Il est conseillé de bien choisir le logo à utiliser en fonction du fond sur lequel vous voulez l’afficher.
La modification, ajout ou suppression de l’ombrage autre que tel que présenté dans les logos ne sont pas autorisés (cela est valable plus globalement dans tout le design, le choix de mettre des ombres portées fait partie des réflexions de design, ce n’est pas un élément variable).
Officiel
Officiel pour les fonds sombres
Blanc
Noir
Favicons, logos seuls
🚫 Ce qu’on ne doit pas faire
Trop petit (< 16px de hauteur)
Disproportion
Changer la couleur du texte ou l’ombre portée
Changer le sens
Déformation
✅ Ce qu’on peut faire
Modification de la couleur interne pour un évènement
Utilisation seule du logo (sans le texte)
Les couleurs
Ces couleurs sont celles du logo, elles ne sont pas à confondre avec celles du design global de l’interface d’OSRD.
#786ABF #C7B2DE
2.5 - Publication
Section sur les releases
Cette section documente le processus de création d’une publication d’OSRD.
2.5.1 - Processus de publication
Voici comment OSRD est actuellement publié
OSRD possède trois versions : développement (dev), staging et publication.
La version de développement est la version la plus récente et la plus instable de l’application, contenant les dernières fonctionnalités et corrections de bugs en cours de développement.
Processus courant
Les versions staging sont créées tous les jeudis à 12h en taguant l’état actuel du développement.
Si une version staging passe les tests de validation, elle est promue pour devenir la dernière version publication. Cela garantit que seul du code stable et testé est intégré dans les versions de production.
Le processus de publication suit ce workflow :
- Développement continu dans la branche
dev - Tags de
staginghebdomadaires les jeudis à 12h - Tests de validation de la version
staging - Promotion des builds
stagingvalidés au statut de publication
Développement Staging publication
(instable) (test) (stable)
[Branche Dev] |
| |
|---> Jeudi 12h |
| [Tag Staging] |
| | |
| Validation |
| Tests |
| | |
| o---> Si Passage --> Nouvelle
| Tests publication
[Suite Dev] |
| |
V V
Iteration de stabilisation et d’innovation
Toutes les 11 semaines, une itération (2 semaines) est consacrée à la stabilisation et l’innovation.
Le but est de s’assurer de publier une version stable à cette échéance (accent mis sur la détection et correction de bugs). Une version staging est créée le vendredi soir avant cette itération de stabilisation et d’innovation (échéance pour ajouter des fonctionnalités ou refontes).
Le processus de travail durant cette période est le suivant :
- La branche
devconserve sa vie courante (afin d’éviter de bloquer les travaux ou de créer des conflits supplémentaires) - Un focus particulier est effectué sur la correction de bug avec le processus suivant :
- Une PR de correction est ouverte puis mergée sur la
dev - Puis une nouvelle PR est ouverte pour reporter la correction sur la branche
staging
- Une PR de correction est ouverte puis mergée sur la
Un rapport de bug requiert donc 2 PRs pour être clos. Ce processus est maintenu pendant 2 semaines (même si les tests de validations sont corrects dès la première semaine).
2.5.2 - Publier une nouvelle version
Comment publier une nouvelle version
Toutes les versions d’OSRD sont accessibles ici
Le processus de création d’une nouvelle version est le suivant :
- Nous publions toujours sur une version testée de l’application (branche staging)
git switch staging && git pull
- Créer un tag git annoté
- Nous utilisons le versionnage sémantique
git tag -a vx.y.zavec le messageRelease x.y.z(la plupart du temps, utilisez la dernière version et incrémentez la version patch)git push --tags
- Créer une release GitHub
- Créer une nouvelle release GitHub ici
- Sélectionner le tag créé
- Générer les notes de version
- Renommer la release ainsi : “Version x.y.z”
- Cocher la case “Set as a pre-release”
- Appliquer le format du changelog
- Vous pouvez ensuite publier la release ou sauvegarder le brouillon si vous souhaitez y revenir plus tard
- Une action GitHub devrait être déclenchée automatiquement.
- Poster le lien de la release créée sur Matrix. Suggérer aux développeurs de revoir la release.
Format du changelog
- Utiliser la structure suivante :
## What's Changed
### Features :tada:
### Code refactoring :recycle:
### Bug fixes :bug:
## New Contributors
<!-- Copy from the generated release notes -->
...
<!-- Copy from the generated release notes -->
**Full Changelog**: ...
- Répartir les différentes pull requests
- Fusionner ou regrouper les PR quand cela a du sens. Exemples :
- PR de mise à jour des dépendances (fusionner)
- PR en plusieurs parties (fusionner)
- Une grande fonctionnalité implémentée par plusieurs PR (regrouper)
- Reformuler les titres des PR. Ils doivent être compréhensibles pour un collaborateur externe
3 - Référence technique
Machinerie interne et APIs
Les guides de référence technique contiennent des références techniques pour les API et autres aspects de la machinerie OSRD. Ils présentent son fonctionnement et la manière de l’exploiter en partant du principe que les concepts clés de base sont maîtrisés.
3.1 - Architecture
Détails lié à l’architecture de OSRD
Les documents d’architecture permettent de comprendre comment OSRD fonctionne globalement.
3.1.1 - Flux des données
Schéma des flux des données d’osrd

3.1.2 - Services
OSRD’s services architecture
Non traduit : veuillez sélectionner une autre langue
3.2 - Documents de conception
Détails liés à la conceptions de solutions techniques
Les documents de conceptions décrivent comment et pourquoi un composant logiciel a été conçu, de l’exposition du problème à la solution technique, en passant par le chemin pris pour y arriver.
3.2.1 - Poste d'aiguillage
Décrit le fonctionnement du poste d’aiguillage virtuel
Le modèle de simulation définit le rôle et comportement des différents objets simulés au sein d’OSRD.
Cette modélisation est un compromis entre de multiples enjeux:
- fidélité de la simulation
- interprétabilité des résultats
- adaptabilité du modèle à différentes technologies et usages, que cela soit en terme de signalisation, de poste d’aiguillage, ou d’usage des données
En particulier, certaines subtilités propres aux systèmes pratiques ont été sacrifiées sur l’autel de la compatibilité et de l’interprétabilité:
- un signal doit forcément s’addresser à un train en particulier: les signaux n’ont pas d’aspect par défaut; ils n’existent que pour être vus
- les itinéraires / routes sont formées à destination d’un train en particulier
Ce document est une description du modèle de fonctionnement cible d’OSRD. Il a pour objectif de renseigner développeurs et experts métiers sur le fonctionnement du simulateur. Des changements y sont apportés au fil de l’évolution du projet.
Ce modèle est en cours d’implémentation
Architecture
flowchart TD
%%%% NODES
train[Train]
%% ↓
signaling[Signalisation]
%% ↓
routing[Routage]
ordering[Ordonnancement]
%% ↓
reservation[Réservation]
%% ↓
location[Localisation]
movable-elements["Éléments mobiles"]
%%%% EDGES
train -- réagit à --> signaling
train -- réclame les itinéraires --> ordering
ordering -- commande --> routing
signaling -- observe --> reservation
routing -- observe et réserve --> reservation
reservation -- observe --> location
reservation -- actionne --> movable-elements
train -- informe --> location
%%%% CLICKABLE LINKS
click train href "./train/" _self
click ordering href "./ordering/" _self
click signaling href "./signaling/" _self
click routing href "./routing/" _self
click reservation href "./reservation/" _self
click location href "./location/" _self
click movable-elements href "./movable-elements/" _selfPistes d'évolution
- Gestion des overlaps
Remerciements
Par ordre alphabétique:
- Christophe Mémin
- Djamal Bellebia
- Gilles Dessagne
- Nathanaël Dias
3.2.1.1 - Éléments mobiles
Gère l’état des organes de commande des aiguilles, passages à niveau, …
Description
Chaque élément mobile, aiguille ou passage à niveau, a une liste d’états possibles. Ces états sont mutuellement exclusifs.
Dépendances
statiqueune liste d’éléments mobilesstatiqueliste des états possibles de chaque élément mobile
Opérations possibles
- observer un élément mobile
- verrouiller / déverrouiller un élément mobile
- bouger un élément mobile
3.2.1.2 - Localisation
Fournit les informations de position des trains sur le réseau
Description
La couche de localisation permet à d’autres modules de simulation de suivre le déplacement du train dans l’infrastructure. L’infrastructure ferroviaire est découpée en régions appelées zones. Quand on train entre dans une zone, ce module permet d’en être notifié.
Les zones (ou TVDSection / DetectionSection) sont des partitions physiques des voies :
- capables de détecter la présence d’un train
Exigences de conception
- il doit être possible de suivre les changements d’occupation d’une zone
- il devra être possible de suivre les déplacements d’un train
- il devra être possible d’implémenter un système de bloc mobile
Dépendances
statiqueune liste de zones
Opérations
- Occuper une zone
- Libérer une zone
- Observer les changements d’occupation d’une zone
3.2.1.3 - Reservation
Gère l’état de réservation des zones
Le mot réservation ici a pour sens réservation de la resource itinéraire, et non le sens commande planifiée d’itinéraire
Description
Les zones (ou TVDSection / DetectionSection) sont des partitions physiques des voies :
- capables de détecter la présence d’un train
- qui fournissent un service de réservation à l’usage des routes
Chaque zone a un certain nombre de configurations différentes. Par exemple, une zone sans aiguille aura deux configurations :
- sens pair
- sens impair
Une zone avec une aiguille aura 4 configurations possibles :
- sens pair voie principale
- sens impair voie principale
- sens pair voie déviation
- sens impair voie déviation
Chaque zone ne peut être réservée que pour une configuration donnée à la fois, mais peut être réservée simultanément par plusieurs routes. Une zone ne peut changer de configuration que lorsqu’elle n’est pas réservée.
En discutant avec des experts métiers, vous entendrez parler d’enclenchements: le terme viens de l’époque où les postes de signalisations étaient entièrement mécaniques. Les enclenchements étaient alors des objets physiques qui empêchaient certaines configurations.
Une conséquence de cet héritage historique et que beaucoup de règles ferroviaires sont exprimées par contraintes au lieu d’être exprimées par garanties. Un enclenchement, c’est une garantie qu’une situation particulière ne peut pas se produire.
État dynamique d’une zone
enum ZoneState {
/// A list of active reservations.
/// Each reservation requires a particular configuration to be upheld.
reservations: VecDeque<ZoneReservation>,
}
struct ZoneReservation {
/// The train which requires this reservation
train: TrainHandle,
// The configuration required for this reservation
requirements: ZoneRequirements,
/// The state of this reservation
status: ZoneReservationStatus,
}
enum ZoneReservationStatus {
/// In the process of being reserved, but not yet ready
PRE_RESERVED,
/// The train can arrive anytime
RESERVED,
/// The train is inside the zone
OCCUPIED,
/// The zone is pending release
PENDING_RELEASE,
}
struct ZoneRequirements {
entry: Option<DirDetector>,
exit: Option<DirDetector>,
movable_elements: Map<MovableElement, MovableElementConfig>,
}
impl ZoneState {
/// Get the combined requirements for all the currently active reservations
fn get_combined_requirements(&self) -> Option<ZoneRequirements> {
return self.reservations
.map(|res| &res.requirements)
.reduce(|a, b| ZoneRequirements::combine(a, b))
}
}
Exigences de conception
- Les zones doivent pouvoir être verrouillées dans une configuration particulière.
- Il doit être possible pour plusieurs routes de partager une réservation de configuration.
- Il doit être possible d’observer l’évolution de statut d’une réservation.
- Il doit être possible de faire évoluer le statut d’une réservation.
Dépendances
statiqueles détecteurs qui délimitent chaque zonestatiqueles aiguilles dans chaque zonedynamiquecapacité d’observer l’occupation des zonesdynamiquecapacité d’actionner les éléments mobiles
Opérations
- espacement: Observer l’état d’une zone
- routage: Verrouiller et déverrouiller la zone : permet d’obtenir un droit d’action. Toutes les opérations en écriture nécessitent d’avoir acquis le verrou.
- routage: Attendre que toutes les réservations d’une zone expirent
- routage: Pré-réserver une configuration de zone
- routage: Confirmer la réservation d’une zone
- routage: Attendre que la réservation de la zone soit occupée par son train
- routage: Relacher une réservation de zone
3.2.1.4 - Routage
Gère le cycle des routes
Description
- Les routes ont pour responsabilité d’autoriser le déplacement des trains dans l’infrastructure. Elles doivent se terminer à un point où l’arrêt du train est prévu (en terme de signalisation, pas voyageur).
- Les routes sont assimilables à des itinéraires, ou à des suites d’itinéraires et d’installations de pleine voie.
- Les routes n’ont pas de lien direct avec le cantonnement et la signalisation. Elles nourrissent des informations sur la disponibilité des voies qui sont utilisées par le cantonnement et la signalisation.
- Une route est un chemin de détecteur en détecteur. Elle représente une portion de chemin qu’il est sûr pour un train d’emprunter.
- Les routes ont des points de libération, qui sont des détecteurs qui délimitent quand détruire l’itinéraire, ce qui permet d’implémenter transit souple, rigide, et entre-deux.
- Une route peut être à nouveau formée alors qu’un train est déjà en train de la parcourir. Cela permet à plusieurs trains de se suivre sur la même route.
Cycle de vie d’une route
Les routes n’ont pas d’état, mais leur commande donne lieu à une suite d’événements systématique :
- le système commande toutes les routes sur le trajet du train dans l’ordre, sans attendre
- la commande doit être acceptée par le régulateur
- lorsque le régulateur accepte la commande, la formation commence
- le droit d’action de chaque zone de la route est acquis, selon un ordre global
- en parallèle pour toutes les zones:
- si la zone n’est pas dans la configuration souhaitée:
- si elle est déjà réservée, attendre que les réservations expirent
- sinon, la mettre dans la configuration souhaitée en déplaçant les aiguilles
- pré-réserver la zone pour le passage du train
- le droit d’action de la zone est cédé
- si la zone n’est pas dans la configuration souhaitée:
- une fois que la formation est terminée, la route est établie
- pour chaque zone, transformer la pré-réservation du train en réservation
- dès que la route est établie, un processus de destruction de la route commence
- pour chaque zone de la route donnant lieu à une libération
- attendre que le train quitte la zone (que la réservation passe de l’état
OCCUPIEDà l’étatPENDING_RELEASE) - libérer la réservation des zones du début de la route jusqu’à la zone actuelle
- attendre que le train quitte la zone (que la réservation passe de l’état
- pour chaque zone de la route donnant lieu à une libération
Piste d'évolution
Certains postes d’aiguillages ont un enclenchement entre itinéraires de sens contraire (affrontement) qui empêche l’activation d’une route en menant à une zone avec un transit en sens contraire. Il serait envisageable de réserver une zone supplémentaire à la fin du chemin protégé par la route, par sécurité.Piste d'évolution
Certains itinéraires en gare ne permettent pas le partage du chemin par plusieurs trainsPiste d'évolution
En pratique, il pourrait être intéressant d’introduire une notion de route partielle afin de réduire le nombre de routes nécessaires: une route partielle est une portion de route qu’il n’est pas sûr d’activer indépendamment.Exigences de conception
Le système doit, indirectement ou directement:
- permettre à la signalisation de déterminer si une section de voie est prête à être empruntée.
- permettre l’ordonnancement des trains selon des critères configurables.
- permettre la destruction progressive (transit souple) de l’itinéraire après le passage du train.
- il doit être possible d’avoir plusieurs processus de commande actifs au même moment pour la même route, afin de supporter des trains qui se suivent
Dépendances
statiquele chemin des routes de détecteur à détecteurstatiquela position requise des aiguilles, par zonestatiqueles points de libération des zones (qui implémentent le transit souple / rigide)dynamiquerégulateursoumettre des commandesdynamiqueréservationacquérir et relacher un droit d’action par zonedynamiqueréservationattendre que les réservations d’une zone expirentdynamiqueéléments mobilesdéplacer des aiguillesdynamiqueréservationpré-réserver une zonedynamiqueréservationpromouvoir une pré-réservation en réservationdynamiqueréservationlors de la destruction de la route, attendre qu’une réservation passe enPENDING_RELEASEdynamiqueréservationlibérer une réservation
Opérations
- commander une route: démarre un processus asynchrone qui ne se terminera que lorsque la route aura été établie. Un processus de destruction doit démarrer dès que la route est établie.
Notes de conception
Ces notes permettent d’expliquer les décisions qui ont été prises, afin de pouvoir plus aisément les comprendre et évoluer.
Informer la signalisation
Sachant que:
- il peut y avoir beaucoup de zones partant d’un même point, il est préférable d’éviter de contraindre les signaux à observer une liste de routes
- il est potentiellement difficile d’associer un état clair à chaque route
Il en ressort plusieurs manières d’informer la signalisation de la navigabilité des voies:
- soit directement, en faisant observer à la signalisation les points d’entrée des routes. Si plusieurs routes partent du même endroit, elles partageraient un objet entrée:
- moins de complexité dans la couche de réservation, plus de complexité dans la couche de routage
- soit indirectement, via la couche de réservation des zones, qui auraient un état supplémentaire pour marquer leur navigabilité:
- moins de complexité dans la couche de routage, plus de complexité dans la couche de réservation
avantagele processus d’activation des routes n’aurait pas besoin d’attendre l’arrivée du train, la couche de réservation s’en occuperait.avantagedécouplage entre routage et cantonnement / signalisation.
La seconde option a été choisie, car :
- elle permet d’avoir un couplage moins fort entre la signalisation et les routes.
- elle évite aussi au processus d’activation des routes d’attendre le passage du train alors que la couche de réservation le fait déjà.
Cycle de vie des routes et état des zones
Plusieurs enjeux motivent le cycle de vie des routes et l’état des zones :
- d’une part, l’état des zones est au cœur de la détection de conflit : il doit être possible d’extraire d’une simulation d’un train seul ses besoins en ressources
- d’autre part, il faut qu’une simulation multi-train fonctionne correctement : le temps de déplacement des aiguilles selon la configuration actuellement en place, en particulier, est un point de friction important
3.2.1.5 - Ordonnancement
Décide de l’ordre de formation des itinéraires
Cette page est une ébauche, contribuez-y!
Définition
La couche d’ordonnancement a pour responsabilité d’établir l’ordre de commande des itinéraires, et par conséquent, l’ordre de passage des trains. La méthode exacte utilisée pour prendre cette décision n’importe pas, du moment qu’elle garantit que la simulation se termine (elle ne doit pas amener de trains en nez-à-nez, ou créer d’autres cas de figure de blocage).
Il est possible d’implémenter un module d’ordonnancement via des tableaux d’ordre de succession des trains aux aiguilles.
Exigences de conception
- Il doit être possible de connecter n’importe quel algorithme d’ordonnancement
- Le module d’ordonnancement doit approuver les commandes de routes.
Opérations
- train: Des itinéraires sont commandés pour chaque trains, aussi loin et aussi tôt que possible. L’approbation de la commande est soumise au régulateur, qui peut la retarder indéfiniment, selon des critères de son choix.
3.2.1.6 - Train
Représente un train dans la simulation
Description
Les contraintes sur ce qu’est un train sont relativement faibles. Il doit seulement avoir un identifiant, qui permet aux autres systèmes de garder des références vers des trains.
Exigences de conception
- Les trains occupent les zones.
- Les trains doivent être suivis pour préserver leur ordre de passage.
- Les trains ont pour responsabilité de demander les itinéraires devant eux.
3.2.2 - Signalisation
Description du modèle de signalisation
Non traduit : veuillez sélectionner une autre langue.
3.2.3 - Détection de conflit
Détecter les planifications horaires irréalistes
Non traduit : veuillez sélectionner une autre langue.
3.2.4 - Calcul de marche v3
Modèle et design d’API pour les calculs de marche
Non traduit : veuillez sélectionner une autre langue.
3.2.5 - Recherche de sillons de dernière minute (STDCM)
OSRD permet d’ajouter un nouveau train dans une grille horaire déjà établie, sans générer aucun conflit avec les autres trains. L’application directe de cette fonctionnalité est appelée la recherche de sillon de dernière minute.
L’acronyme STDCM (Short Term Digital Capacity Management) est utilisé pour parler du concept en général.
3.2.5.1 - Contexte métier
Quelques définitions :
La capacité
La capacité, dans ce contexte, correspond à la possibilité de réserver des éléments d’infrastructure pour permettre le passage d’un train.
La capacité s’exprime en fonction de l’espace et du temps : la réservation d’un élément peut bloquer une zone précise qui devient inaccessible aux autres trains, et cette réservation se fait sur un intervalle de temps.
On peut la représenter sur un graphique, avec le temps en abscisse et la distance parcourue sur un chemin en ordonnée.
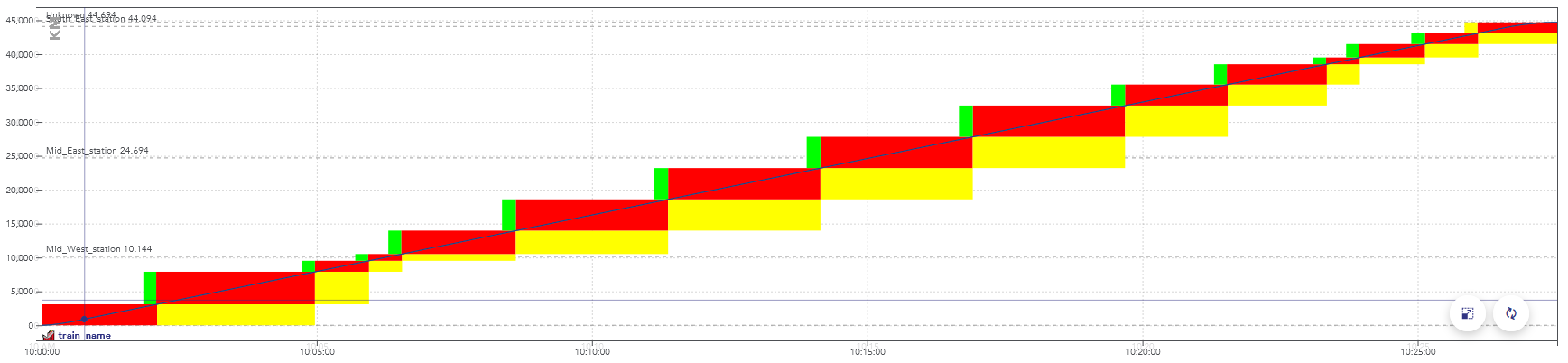
Exemple d’un graphique espace-temps montrant le passage d’un train.
Les couleurs représentent ici les aspects des signaux, mais montrent également une consommation de la capacité : quand ces blocs se superposent pour deux trains, ils sont en conflit.
Deux trains d’une grille horaire sont en conflit quand ils réservent en même temps un même objet, dans des configurations incompatibles.
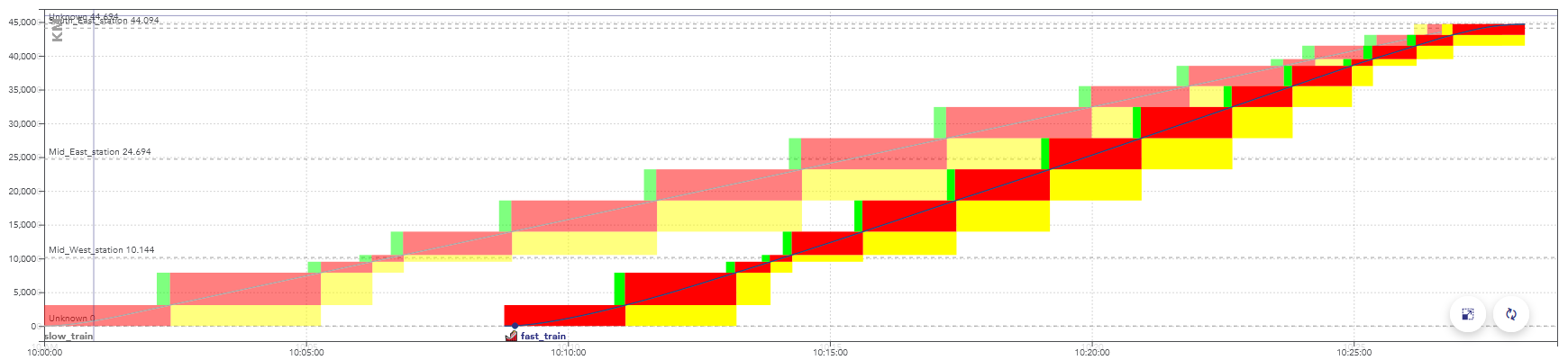
Exemple d’un graphique espace-temps avec conflit : le second train est plus rapide que le premier, ils sont en conflit sur la fin du trajet, quand les rectangles se superposent.
En essayant de simuler cette grille horaire, le second train serait ralentis par des signaux indiquant de ralentir, provoqués par la présence du premier train.
La consommation de capacité est souvent représentée sous la forme de rectangles car, dans les systèmes de signalisation les plus simples, il s’agit de réservations d’une zone fixe dans l’espace pendant un intervalle de temps donné.
Les sillons horaires
Un sillon correspond à une réservation de capacité pour le passage d’un train. Il est fixé dans l’espace et dans le temps : le temps de départ et le chemin emprunté sont connus. Sur les graphiques espace-temps de cette page, un sillon correspond à l’ensemble des blocs pour un train.
Dans un fonctionnement habituel, le gestionnaire d’infrastructure (ex : SNCF Réseau) propose des sillons à la vente pour les entreprises ferroviaires (ex : SNCF Voyageurs).
À une date donnée avant le jour de circulation prévu, tous les sillons sont attribués. Mais il peut rester assez de capacité pour faire rouler plus de trains. Il est possible de placer des trains entre les sillons déjà établis, quand ces derniers sont suffisamment espacés ou n’ont pas trouvé d’acheteurs.
La capacité restante après l’attribution des sillons est appelée la capacité résiduelle. Le problème traité ici est la recherche de sillons dans celle-ci.
3.2.5.2 - Module de recherche de sillons
Ce module gère la recherche de solution.
Les entrées et sorties sont fortement simplifiées et abstraites pour simplifier le problème au maximum et permettre des tests efficaces.
Pour décrire son fonctionnement en quelques phrases : l’espace de solutions est représenté sous forme d’un graphe qui encode le temps, la position et la vitesse. Une recherche de chemin est ensuite effectuée dans ce graphe pour trouver une solution. Le graphe est calculé au fil de son exploration.
Ce graphe peut d’une certaine manière être vu comme une forme d’arbre de décision, si différents chemins peuvent mener au même nœud.
3.2.5.2.1 - Parcours de l'infrastructure
La première chose à définir est comment un train se déplace sur l’infrastructure, sans prendre en compte les conflits pour l’instant.
On a besoin d’une manière de définir et d’énumérer les différents chemins possibles et de parcourir l’infrastructure, avec plusieurs contraintes :
- Le chemin doit être compatible avec le matériel roulant donné (électrification, gabarit, systèmes de signalisation)
- À n’importe quel point, on doit être en mesure d’accéder aux propriétés du chemin depuis le point de départ jusqu’au point considéré. Cela inclus les routes et les cantons.
- Dans certains cas, on doit savoir où le train ira après le point actuellement évalué (pour une détection de conflits correcte).
Pour répondre à ce besoin, une classe InfraExplorer a été implémentée.
Elle utilise les cantons (section de signal en signal) comme subdivision
principale.
Elle est composée de 3 sections : le canton courant, les prédécesseurs,
et les cantons suivants.

Dans cet exemple, les flèches vertes sont les cantons précédents. Ce qui se produit dessus est considéré comme immuable.
La flèche rouge est le canton actuellement exploré. C’est à cet endroit que les simulations du train et de la signalisation sont effectuées, et que les conflits sont évités.
Les flèches bleues sont les cantons suivants. Cette section
n’est pas encore simulée, elle existe seulement pour savoir
où le train ira ensuite. Dans cet exemple, elle indique
que le signal en bas à droite peut être ignoré, seul
le chemin du haut sera utilisé.
Le chemin du bas sera évalué dans une autre instance de
InfraExplorer.
Plus de détails sur la classe et son interface sont présents sur la version anglaise de la page.
3.2.5.2.2 - Détection de conflits
Maintenant qu’on sait quels chemins peuvent être utilisés, on doit déterminer à quel moment ces chemins sont libres.
La documentation (en anglais seulement) de la détection de conflits explique comment elle est réalisée en interne. Pour résumer, un train est en conflit avec un autre quand il observe un signal lui indiquant de ralentir. Dans notre cas, une solution où cette situation se produit est considérée comme invalide, le train doit arriver au signal donné plus tard (ou plus tôt) quand le signal n’est plus contraignant.
Cependant, la détection de conflit doit être réalisée de manière incrémentale, ce qui veut dire que :
- Quand une simulation est effectuée jusqu’à t=x, tous les conflits qui arrivent avant t=x doivent être connus, même s’ils sont indirectement provoqués par un signal vu à t > x plus loin sur le chemin.
- Les conflits et utilisations de ressources doivent être identifiés dès qu’ils se produisent, même si le temps de fin d’utilisation n’est pas encore défini.
Pour que ce soit possible, on doit être en mesure de savoir où le train ira après la section actuellement simulée (cf exploration de l’infrastructure )
Pour gérer ce cas, le module de détection de conflit
peut renvoyer une erreur quand il est nécessaire d’avoir
plus d’information sur la suite du chemin. Quand ce cas
se produit, les objets InfraExplorer sont clonés
pour étendre les chemins.
3.2.5.2.3 - Représentation de l'espace de solutions
Principe général
Le problème reste une recherche de graphe. En représentant l’espace de solution sous forme de graphe, il est possible de réutiliser nos outils déjà existants de recherche de chemin.
Le graphe produit de la position, du temps, et de la vitesse est utilisé. Autrement dit, chaque élément du graphe contient (entre autres) ces 3 variables.
Chaque arête du graphe est calculée avec un calcul de marche pour connaître l’évolution de la vitesse et de la position dans le temps.
Représentation visuelle
Le graphe de départ représente l’infrastructure physique
Il est ensuite “dupliqué” à des temps différents
Puis des nœuds sont reliés de manière à refléter le temps de parcours
Précisions
- Le graphe est construit au fil de l’exploration.
- Une discrétisation est faite au niveau du temps, uniquement pour évaluer ce qui a déjà été visité. Si le même emplacement est visité une seconde fois, il faut une certaine différence de temps pour estimer qu’il n’est pas déjà visité.
- Toutes les arêtes sont réalisées avec des calculs de marche
- La vitesse n’est pas discrétisée ni utilisée pour estimer quel emplacement est déjà visité, mais elle fait partie des calculs.
- Par défaut, tous les calculs sont faits en allant à la vitesse maximale. Les ralentissements sont ajoutés seulement quand ils sont nécessaires.
Exemple
Par exemple, avec l’infrastructure suivante en se basant sur
le graphe des voies :

Explorer le graphe des sillons possibles peut donner ce
type de résultat :

3.2.5.2.4 - Discontinuités et retours en arrière
Le problème des discontinuités
Au moment d’explorer une arête du graphe, on effectue un calcul de marche pour connaître l’évolution de la vitesse. Mais il n’est pas possible de voir plus loin que l’arête en question, ce qui est gênant pour calculer les courbes de freinages qui peuvent nécessiter de commencer à freiner plusieurs kilomètres avant l’arrivée.
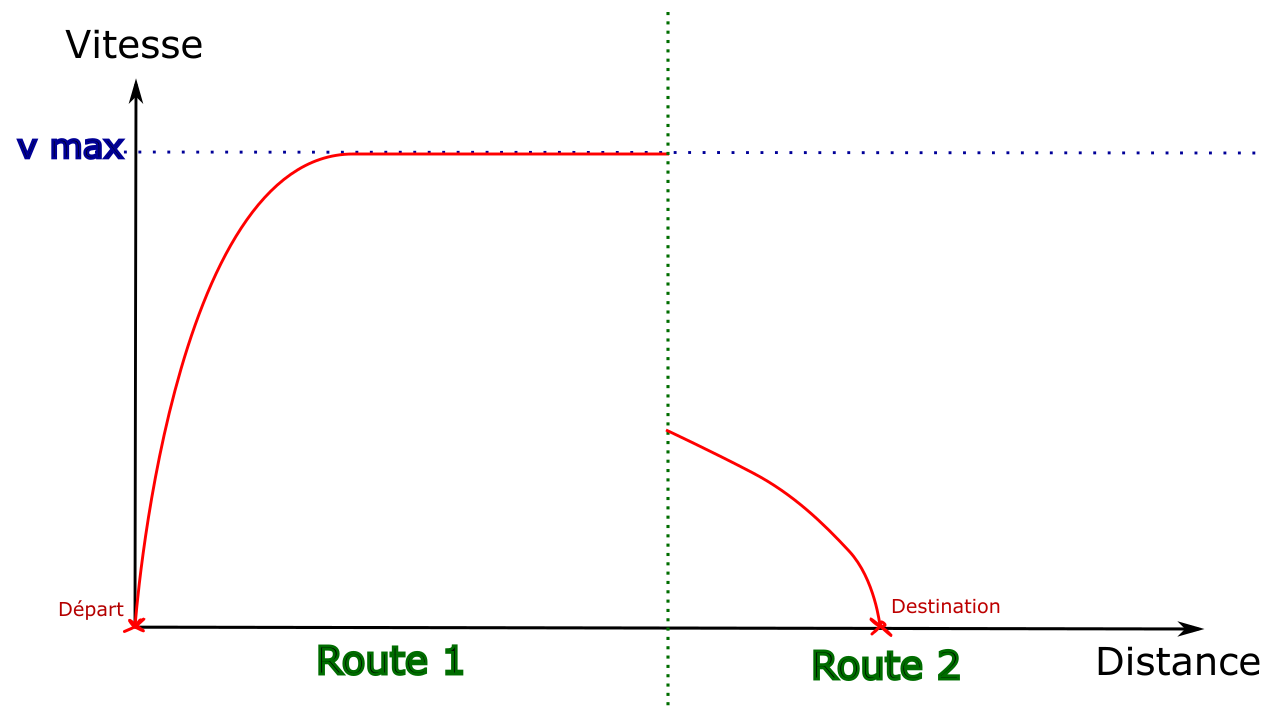
Cet exemple illustre le problème : par défaut la première arête est explorée en allant à la vitesse maximale. C’est seulement en explorant la seconde arête que la destination devient visible, sans que la distance restante soit suffisante pour s’arrêter.
La solution : revenir en arrière
Pour régler ce problème, lorsqu’une arête est générée avec une discontinuité dans les courbes de vitesse, l’algorithme revient sur les arêtes précédentes pour en créer des nouvelles qui incluent les décélérations.
Pour donner un exemple simplifié, sur un chemin de 4 routes où le train peut accélérer ou décélérer de 10km/h par route :
![]()
Pour que le train s’arrête à la fin de la route 4, il doit être au plus à 10km/h à la fin de la route 3. Une nouvelle arête est alors créée sur la route 3 qui finit à 10km/h. Une décélération est ensuite calculée à rebours de la fin de la route vers le début, jusqu’à retrouver la courbe d’origine (ou le début de l’arrête).
Dans cet exemple, la discontinuité a seulement été déplacée vers la transition entre les routes 2 et 3. Le procédé est ensuite réitéré sur la route 2, ce qui donne le résultat suivant :
![]()
Les anciennes arêtes sont toujours présentes dans le graphe, elles peuvent mener à d’autres solutions.
3.2.5.2.5 - Contourner les conflits
En explorant le graphe, il arrive souvent de tomber sur des situations qui mèneraient à des conflits. Il faut être en mesure de rajouter du délai pour les éviter.
Décalage du temps de départ
Dans les paramètres de l’algorithme, le temps de départ est donné sous la forme d’une fenêtre : un temps de départ au plus tôt et au plus tard. Tant que c’est possible, il est toujours préférable de décaler le temps de départ pour éviter les conflits.
Par exemple : un train doit partir entre 10:00 et 11:00. En partant à 10:00, cela provoque un conflit, le train doit entrer en gare d’arrivée 15 minutes plus tard. Il suffit de faire partir le train à 10:15 pour régler le problème.
Dans OSRD, cette fonctionnalité est gérée en gardant une trace, à chaque arête, du décalage maximal du temps de départ qui pourra être ajouté sur la suite du parcours. Tant que cette valeur est suffisante, tous les conflits sont évités par ce moyen.
Le décalage du temps de départ est une valeur stockée sur chaque arête et additionnée à la fin de la recherche de chemin.
Par exemple :
- un train doit partir entre 10:00 et 11:00. La recherche commence avec un délai maximal de 1:00.
- Après quelques arêtes, une non-disponibilité est constatée 20 minutes après notre passage. La valeur passe donc à 20 minutes pour la suite du parcours.
- Le temps de départ est ensuite décalé de 5 minutes pour contourner un conflit, modifiant le décalage maximal à 15 minutes.
- Ce procédé continue jusqu’à arriver à la fin du trajet, ou jusqu’au point où il faut ajouter plus de délai.
Marges de construction
Quand la valeur de décalage maximal du temps de départ tombe à 0, il faut rajouter du délai entre deux points du parcours du train.
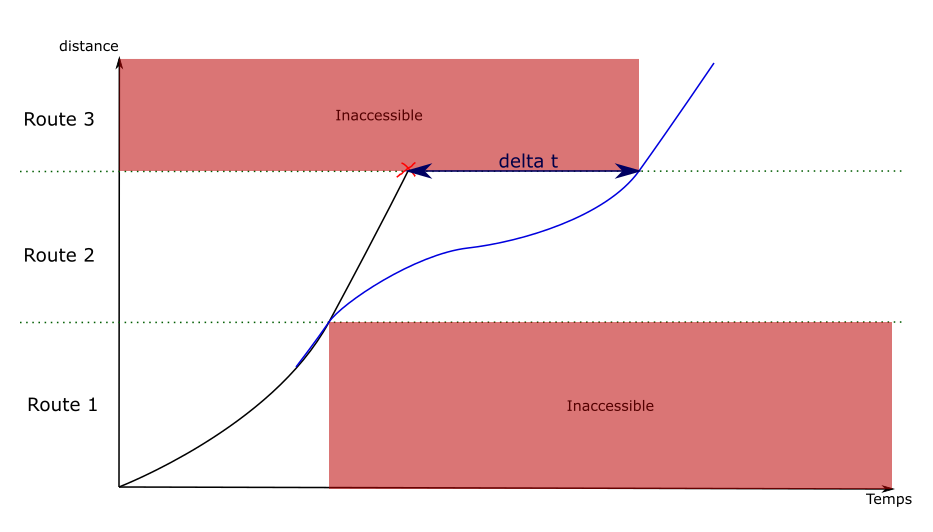
Le principe est le même que pour régler les discontinuités de vitesse : le graphe est parcouru en arrière pour créer de nouvelles arêtes.
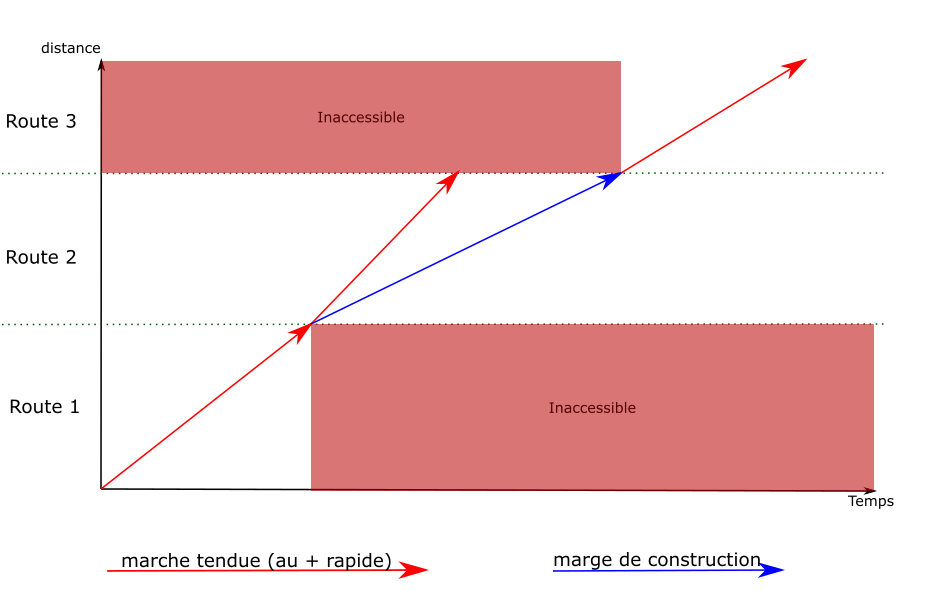
La marge de construction est une fonctionnalité du calcul de marche permettant d’ajouter un délai donné entre deux points du parcours.
Post-processing
Les marges de constructions étaient calculées pendant l’exploration du graph, mais ce procédé était trop couteux en temps de calcul. On effectuait des dichotomies sur des simulations qui pouvaient s’étendre sur des portions importantes du chemin.
On a seulement besoin de savoir si la marge de construction peut être réalisée sans provoquer de conflit. Des heuristiques peuvent être utilisées ici tant qu’on est plus restrictif que permissif : une marge impossible doit être identifiée comme telle, mais manquer une solution avec une marge extrêmement serrée n’est pas une mauvaise chose.
Mais avec ce changement, une fois qu’une solution est trouvée, il ne suffit plus de concaténer les résultats de simulation pour obtenir la simulation finale. On doit réaliser une simulation complète avec les vraies marges de construction qui évitent tout conflit. Cette étape se rejoint avec celle décrite pour les marges de régularité, qui est maintenant réalisée même sans marge de régularité spécifiée.
3.2.5.2.6 - Marge de régularité
Une des fonctionnalités qui doit être supportée par STDCM est la marge de régularité. L’utilisateur doit pouvoir indiquer une valeur de marge, exprimée en fonction de la distance ou du temps de parcours, et cette marge doit être ajoutée au trajet.
Par exemple : l’utilisateur peut indiquer une marge de 5 minutes au 100km. Sur un trajet de 42km, un trajet de 10 minutes au plus rapide doit maintenant durer 12 minutes et 6 secondes.
Le problème se situe au niveau de la détection de conflits. En effet, ralentir le train décale l’ensemble du sillon dans le temps et augmente la capacité consommée. La marge doit donc être prise en compte pendant l’exploration pour détecter correctement les conflits.
Pour plus de difficulté, la marge doit suivre le modèle MARECO. La marge n’est pas répartie uniformément sur le trajet, mais selon un calcul qui nécessite de connaître l’ensemble du trajet.
Pendant l’exploration
La principale implication de la marge de régularité est pendant l’exploration du graphe, quand on identifie les conflits. Les temps et les vitesses doivent être baissés linéairement pour prendre en compte les conflits au bon moment. La simulation au plus rapide doit tout de même être calculée car elle peut définir le temp supplémentaire.
Ce procédé n’est pas exact car il ignore la manière dont la marge est appliquée (en particulier pour MARECO). Mais à cette étape les temps exacts ne sont pas nécessaires, il est seulement nécessaire de savoir si une solution existe à ce temps approximatif.
Ce procédé inexact peut sembler être un problème, mais en
pratique (pour la SNCF) les marges de régularités ont en
fait une tolérance entre deux points arbitraires
du chemin. Par exemple pour une marge indiquée à 5 minutes
par 100km, une solution avec la marge entre 3 et 7 minutes
entre deux PR serait acceptable. Cette tolérance ne sera
pas encodée explicitement, mais elle
permet de faire des approximations de quelques
secondes pendant la recherche.
Post-processing
Une fois que le chemin est trouvé, il est nécessaire de faire une simulation finale pour appliquer correctement les marges. Le procédé est le suivant :
- Pour certains points du chemin, le temps est fixé. C’est un paramètre d’entrée de la simulation qui appelle le module de marge. À l’initialisation, le temps est fixé à chaque point d’arrêt.
- Une simulation est réalisée. En cas de conflit, on s’intéresse au premier
- Un point est fixé à la position de ce conflit. Le temps de référence est celui considéré pendant l’exploration.
- Ce procédé est répété itérativement jusqu’à une absence de conflit
3.2.5.2.7 - Détails d'implémentation
Cette page précise certains détails d’implémentation. Sa lecture n’est pas nécessaire pour comprendre les principes généraux, mais peut aider avant de se plonger dans le code.
STDCMEdgeBuilder
Cette classe est utilisée pour simplifier la création d’instances de STDCMEdge,
les arêtes du graphe. Celles-ci contiennent de nombreux attributs,
la plupart pouvant être déterminés en fonction du contexte (comme
le nœud précédent). La classe STDCMEdgeBuilder permet de rendre
certains attributs optionnels et en calcule d’autres.
Une fois instancié et paramétré, un EdgeBuilder a deux méthodes :
Collection<STDCMEdge> makeAllEdges()permet de créer toutes les arêtes possibles dans le contexte donné pour une route donnée. S’il y a plusieurs “ouvertures” entre des blocks d’occupation, une arête est créée par ouverture. Tous les conflits, leurs évitements et les attributs associés sont déterminés ici.STDCMEdge findEdgeSameNextOccupancy(double timeNextOccupancy): Cette méthode permet d’obtenir l’arête passant par une certaine “ouverture” (quand elle existe), identifiée ici par le temps de la prochaine occupation sur la route. Elle est utilisée à chaque fois qu’une arête doit être re-créée dans un contexte différent, comme pour appliquer une marge ou corriger une discontinuité. Elle appelle la méthode précédente.
Recherche de chemin
Evaluation des distances
La fonction utilisée pour déterminer la distance (au sens de la recherche de chemin) détermine quel chemin sera privilégié. Le chemin obtenu sera toujours le plus court en fonction du critère donné.
Ici, deux paramètres sont utilisés : le temps de parcours total et l’heure de départ. Le second a un poids très faible par rapport au premier, pour sélectionner en priorité le chemin le plus rapide. Les détails du calcul sont indiqués dans les commentaires des méthodes concernées.
Heuristiques
L’algorithme de recherche de chemin dans le graphe est un A*, avec une heuristique basée sur les coordonnées géographiques.
Cependant, la géométrie des infrastructures générées sont arbitraires, elle ne correspond pas aux distances indiquées sur les voies. Il est donc possible que, sur ces infrastructures, les chemins obtenus ne soient pas les plus courts.
Il est en théorie possible d’utiliser cette heuristique pour déterminer si le chemin en cours d’exploration pourra mener à une solution dont le temps de parcours ne dépasse pas le maximum. Mais pour la même raison, ajouter ce critère rend STDCM inutilisable sur les infrastructures générées. Plus de détails dans cette issue.
3.2.6 - Timetable v2
Description des évolution des nouveaux modèles timetable et train schedule
Non traduit : veuillez sélectionner une autre langue.
3.2.7 - Authentification et autorisations
Non traduit : veuillez sélectionner une autre langue.
3.2.8 - Gestion d'erreurs dans Editoast
Non traduit : veuillez sélectionner une autre langue.
3.2.9 - Distribution asynchrone et adaptable des tâches entre composants
Non traduit : veuillez sélectionner une autre langue.
3.3 - APIs
Spécifications des interfaces de programmation
Le format utilisé pour décrire une infrastructure ferroviaire est RailJSON, il est décrit dans son schéma JSON.
Ci-dessous se trouve une liste des APIs REST implémentées par OSRD.
3.3.1 - Editoast
3.3.2 - Gateway
4 - Wiki Ferroviaire
Wiki ferroviaire international
Ce wiki a pour objectif de rendre accessible aux développeurs des informations sur le monde ferroviaire.
Cela ne peut se produire que si le contenu est ajouté lorsque nécessaire. Si quelque chose manque, contribuez !
4.1 - Glossaire
Glossaire thématique d’OSRD et du ferroviaire
À compléter : ouvrez une issue en cas de mot manquant
Voir aussi le glossaire relatif à ERTMS/ETCS contenant de nombreux acronymes qui ne sont pas recensés ici.
A
- ADV : Appareil de voie
B
- BA : Block automatique
- BAL : Block automatique lumineux
- BAPR : Block automatique à permissivité restreinte
- BM : Block manuel
- BMCV : BM par circuit de voie
- BMVU : BM de voie unique
- BP/CC : Baisser Pantographe/Couper Courant
C
- CAPI : Cantonnement assisté par informatique
- CC : Commande et contrôle
- CH : Code chantier
- CI : Code immuable : identifie un Point Remarquable (PR) de manière unique en France (voir UIC pour l’international)
- COVIT : Contrôle de vitesse
- CT : Cantonnement téléphonique
D
- DAAT : Dispositif d’arrêt automatique des trains
- DMI : Driver machine interface : dispositif qui permet la communication entre le système bord et le conducteur
- DV : Double voie
E
- EOA : End of authority (fin d’autorisation de mouvement)
- EPSF : Établissement public de sécurité ferroviaire
- ETCS : European train control system (système européen de contrôle commande des trains)
- ERTMS : European rail traffic management system (système européen de gestion du trafic ferroviaire)
- EVC : European vital computer. (ordinateur européen de sécurité) : calculateur de bord qui supervise la marche du train en fonction des données sol et bord
F
- FA : Fermeture automatique
- FS : Full supervision (supervision complète) : mode technique dans lequel le train est supervisé en vitesse et déplacement = marche normale attribuée au train
G
- GI : Gestionnaire d’infrastructure
- GSM/GFU : Global system for mobile communication/Groupe fermé d’utilisateurs
- GSM-R : Global system for mobile communication railways (Système de communication téléphonique pour mobile dédié aux chemins de fer)
- GSM-R Data : Système de transmission de données entre les installations « sol » et les installations « bord » via le réseau GSM-R
I
- ICS : Installations de circulation à contre-sens
- IPCS : Installations permanentes de contre-sens
- IS : Installation de sécurité
- ITCS : Installations temporaires de contre-sens
J
- JRU : Juridical recording unit (Enregistreur des paramètres d’exploitation)
K
- KVB : Contrôle de vitesse par balises
L
- LEU : Line side electronic unit (codeur ERTMS)
- LGV : Ligne à grande vitesse
- LTV : Limitation temporaire de vitesse
M
- MA : Movement authority : autorisation donnée à un train de circuler vers un point donné en tant que mouvement supervisé
N
- Nf : Non franchissable
- NL : Non leading (non en tête) : Mode technique de circulation utilisé pour la double traction ou la pousse
O
- OS : On sight (conduite à vue) : mode technique de circulation qui autorise le conducteur à s’avancer en marche à vue. En ETCS1, le mode OS accompagné du message textuel national « Voie de service » impose la marche en manœuvre pour la réception sur voie de service
P
- PER : Plan d’exploitation de référence
- PI ETCS : Point d’information ETCS : constitué d’une ou plusieurs balises transmettant des informations vers le bord (par exemple PI avancé ou PI signal)
- PK : Point Kilométrique : position géographique basée sur un RK (Repère Kilométrique)
- PL : Pleine ligne
- PLD : Point limite de domaine : point où une transition entre ETCS et un autre système de signalisation a lieu
- PN : Passage à niveau
- PO : Point opérationnel : collection de points représentant un lieu d’intérêt, voir exemple.
- PR : Point remarquable : voir PO
R
- RBC : Radio block center : système centralisé fonctionnant avec les enclenchements afin d’établir et de contrôler l’espacement et le mouvement des trains en envoyant et recevant des informations par radio en ETCS2 ou 3
- RFN : Réseau Ferré National
- RK : Repère Kilométrique : bornes (physiques) placées sur une voie à distance régulière (environ un kilomètre les unes des autres mais pouvant varier) servant à se repérer sur une voie
- RST : Radio sol-train
- RT : Renseignement technique
- RV : Reversing (refoulement) : mode technique de circulation utilisé pour permettre au train de reculer d’urgence sans signaux ni ordre dans une zone prédéfinie. Ce mode n’est pas utilisé sur le RFN
S
- SEL : Section d’électrification. La plus petite portion d’un caténaire pouvant être coupée pour travaux
- SGS : Système de gestion de la sécurité
- SH : Shunting (manœuvre) : mode technique de circulation manœuvre
- SN : System national : mode technique de circulation de niveau STM
- SR : Staff responsible (responsabilité agent) : mode technique de circulation utilisé dans les situations dégradées. Il est utilisable sous la responsabilité respective de l’agent-circulation et du conducteur
- SR : Système de repérage
- SRV : Système de repérage voie : métadonnées et anomalies (données correctives) permettant de faire des calculs de distance entre deux PKs sur une voie
- STDCM : Short-term digital capacity management (recherche de sillons de dernière minute), désigne la fonctionnalité de Last Minute Request
- STM : Specific transmission module (Module spécifique de transmission) : ce dispositif permet à l’ETCS d’utiliser un système de signalisation national
T
- TECS : Tableau lumineux d’entrée à contre sens
- TIV : Tableau indicateur de vitesse
- TIV : Tronçon d’itinéraire de voie (Track Section en anglais).
- TR : Trip : mode technique de circulation entraînant une application irréversible du freinage d’urgence par le système ETCS jusqu’à l’arrêt du train
- TSCS : Tableau lumineux de sortie à contre sens
- TVM : Transmission voie machine
U
- UIC : Union Internationale des Chemins de fer : utilisé également comme un code international pour désigner un Point Remarquable (PR) ; par exemple, le code CI préfixé par 87 (code pour la France) est un code UIC.
V
- VB : Voie banalisée
- VP : Voie principale
- VS : Voie de service
- VU : Voie unique
- VUT : Voie unique temporaire
- VUTP : Voie unique temporaire à caractère permanent
Z
- ZEP : Zone élémentaire de protection : la plus petite portion de voie pouvant être fermée pour des travaux
4.2 - Signalisation
Les signaux, régimes d’exploitation des trains et les systèmes d’espacement des trains
Cette section est destinée à exposer les principes généraux relatifs :
- aux signaux
- aux régimes d’exploitation des lignes
- aux différents systèmes d’espacement des trains
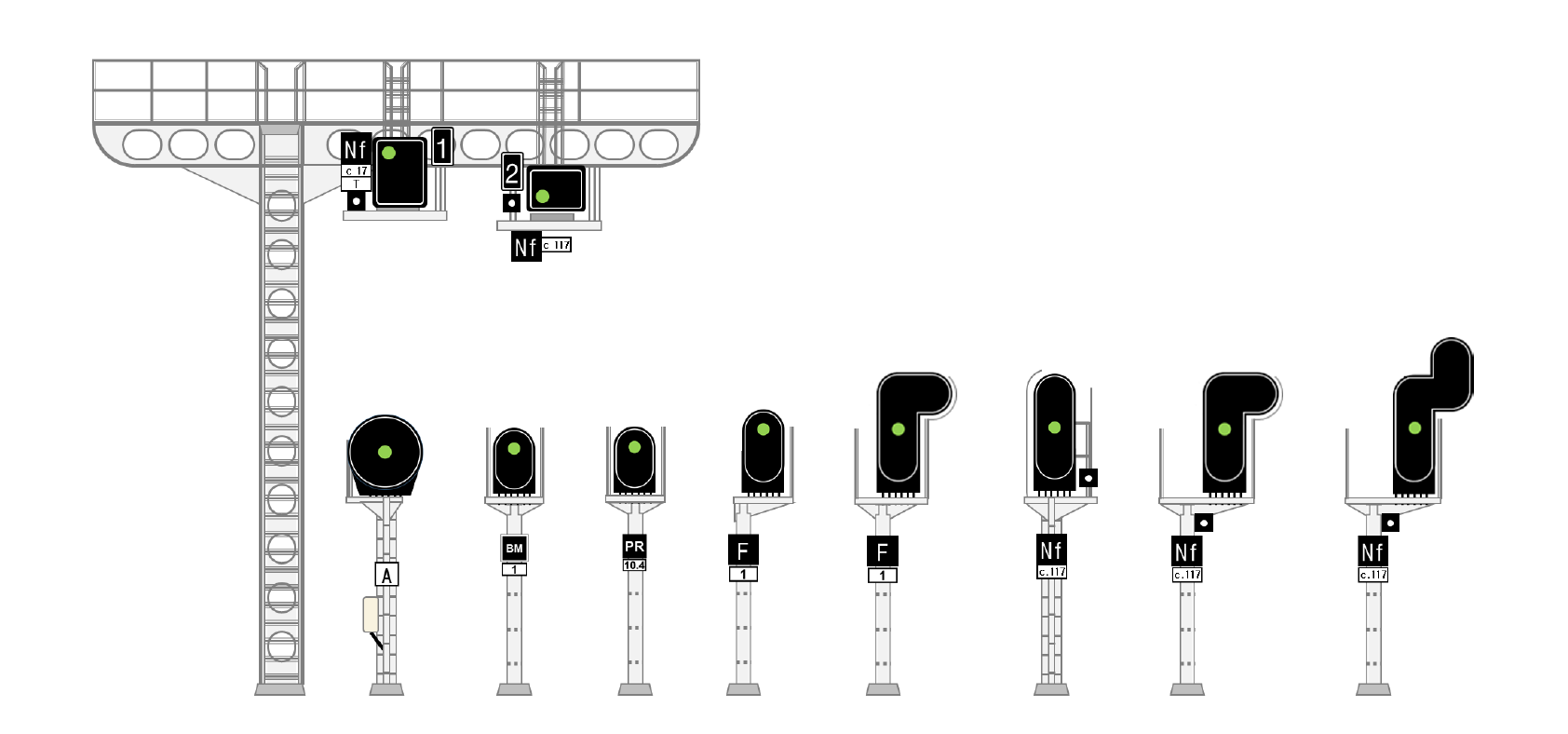
La majorité des informations de cette section sont extraites du document pédagogique de l’Établissement Public de Sécurité Ferroviaire (EPSF) édité le 05 juillet 2017.
4.2.1 - Les risques ferroviaires
Les trains doivent circuler en toute sécurité. Les risques majeurs liés aux circulations ferroviaires sont les suivants :
- le rattrapage des trains qui circulent dans le même sens sur la même voie ;
- la prise en écharpe, c’est-à-dire la collision latérale de trains qui circulent sur des itinéraires convergents ;
- le nez à nez, c’est-à-dire la collision frontale de trains qui circulent en sens contraire sur la même voie ;
- le déraillement ;
- la collision avec un obstacle.
On prévient ces risques notamment par :
- la mise en place d’une signalisation ;
- l’établissement d’un régime d’exploitation de la ligne (double voie, voie banalisée, voie unique) ;
- la mise en place d’un système d’espacement des trains ;
- la mise en oeuvre de procédures d’exploitation.
D’autres dispositifs techniques contribuent également à couvrir ces risques tels que :
- les installations de sécurité, notamment les enclenchements des postes d’aiguillage ;
- le DAAT qui est un dispositif permettant d’assurer l’arrêt automatique des trains en cas de franchissement intempestif d’un point d’information avec signal d’arrêt fermé ;
- le KVB, le COVIT (TVM) sont des exemples de systèmes de contrôle de la vitesse, avec contrôle de franchissement des signaux non franchissables ;
- le système de contrôle commande des trains, intégré dans l’ETCS.
La sécurité des circulations repose aussi sur le respect rigoureux des consignes et instructions opérationnelles par tous les agents concernés par la circulation des trains.
Ces procédures sont de la responsabilité des exploitants ferroviaires. Elles sont décrites dans le manuel du système de gestion de la sécurité (SGS) qu’ils établissent et qui fait l’objet d’une instruction par l’EPSF chargé de délivrer le certificat ou l’agrément de sécurité.
4.2.2 - Les signaux
Principe
Pour transmettre au conducteur des ordres et informations liées à la sécurité des circulations, il est fait usage de signaux. Ces signaux peuvent indiquer des informations relatives aux limites de vitesse, peuvent servir à garantir l’espacement des trains ou donner des indications diverses telles que l’accès à des voies de service, des ouvrages d’art à gabarit réduit, etc.
La signalisation à main

La signalisation au sol
La signalisation au sol est normalement implantée à gauche ou au-dessus de la voie concernée.
Signaux de protection
Les signaux de protection sont destinés à interdire l’accès à un itinéraire, à une aiguille, à un PN, etc. Ils sont généralement manœuvrés depuis des postes par des agents de SNCF Réseau.
Signaux de cantonnement

Les signaux de cantonnement sont destinés à assurer l’espacement des circulations de même sens.
Sur les sections de lignes équipées en block automatique (BA), les signaux de cantonnement se ferment automatiquement dès l’occupation du canton et restent fermés jusqu’à sa complète libération.
Sur les sections de lignes équipées en block manuel (BM), les signaux de cantonnement sont manœuvrés depuis des postes par des agents du service du GI chargé de la gestion des circulations.
Signaux d’annonce d’arrêt

Le carré, le sémaphore et le feu rouge clignotant sont normalement annoncés à distance par un avertissement qui peut lui-même être précédé, en signalisation lumineuse, par un feu jaune clignotant.
Toutefois, les signaux qui ne peuvent être abordés qu’en marche à vue ou en marche en manœuvre ne sont normalement pas annoncés (par exemple, le guidon d’arrêt). Il en est de même des signaux situés sur voie principale à la sortie des gares en impasse.
Signaux d’indication de marche

Le feu vert indique au conducteur que la circulation en marche normale est autorisée, si rien ne s’y oppose.
Sur les sections de ligne où la vitesse des trains est supérieure à 160 km/h, un feu vert clignotant précède généralement l’avertissement ou le feu jaune clignotant.
Signaux de limitation de vitesse
Ils limitent à un taux déterminé la vitesse des trains sur une partie de voie ou au franchissement de certains points particuliers (aiguille, traversée de gare, etc.).
Les limitations permanentes de vitesse (en complément de celles pouvant figurer dans les RT)
- Sur des parties de voie par tableau indicateur de vitesse (TIV) ordinaire

Au franchissement de certains points particuliers (exemple des aiguilles)
- Ralentissement à 30 km/h en signalisation lumineuse
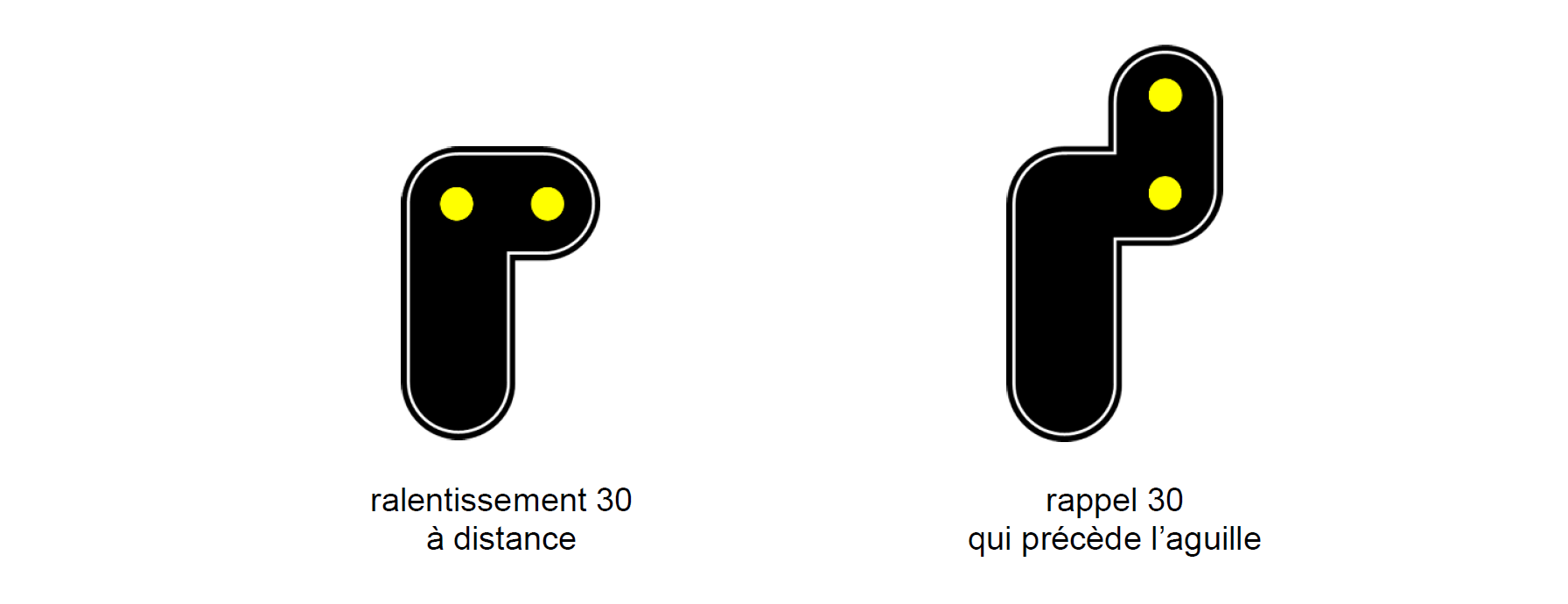

- Ralentissement à 60 km/h en signalisation lumineuse

- TIV mobiles
 Ces tableaux peuvent être lumineux ou mécaniques ; lorsqu’ils sont ouverts ils présentent une bande verticale blanche continue.
Ces tableaux peuvent être lumineux ou mécaniques ; lorsqu’ils sont ouverts ils présentent une bande verticale blanche continue.Si cela est nécessaire, l’emplacement de l’aiguille (ou de la première aiguille dans le cas d’aiguilles successives) est repéré par un chevron pointe en bas.
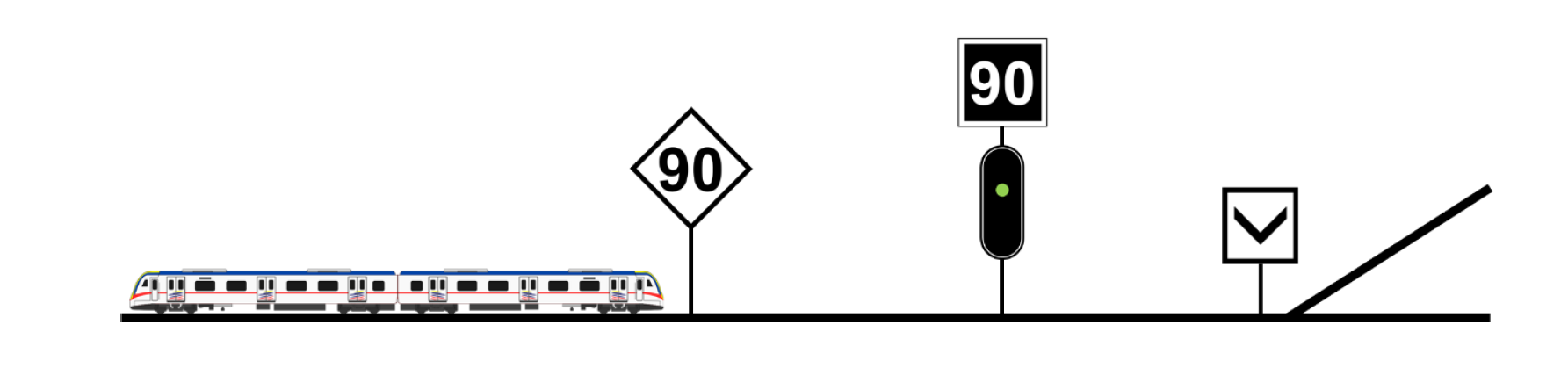

Les limitations temporaires de vitesse
Cette signalisation s’applique sur des parties de voie (chantiers de travaux, etc.) sur lesquelles une limitation temporaire de vitesse doit être observée.

Signaux indicateurs de direction
Ils renseignent les conducteurs sur la direction géographique qui leur est donnée.

Signaux caractéristiques de prescriptions particulières
Ils renseignent les conducteurs sur des particularités.
On trouve :
- des tableaux
- des pancartes
- la bande lumineuse jaune
- la croix de Saint-André (annulation des signaux)
Exemples de tableaux

Exemples de pancartes

Bande lumineuse jaune horizontale

La bande lumineuse jaune horizontale est utilisée en complément de l’avertissement. Elle indique au conducteur que son train est dirigé vers une voie à quai de courte longueur ou bien que sa longueur se trouve réduite.
Croix de Saint-André (annulation des signaux)

Signalisation de sortie de certains faisceaux ou groupes de voies convergentes
Elle peut être constituée de :
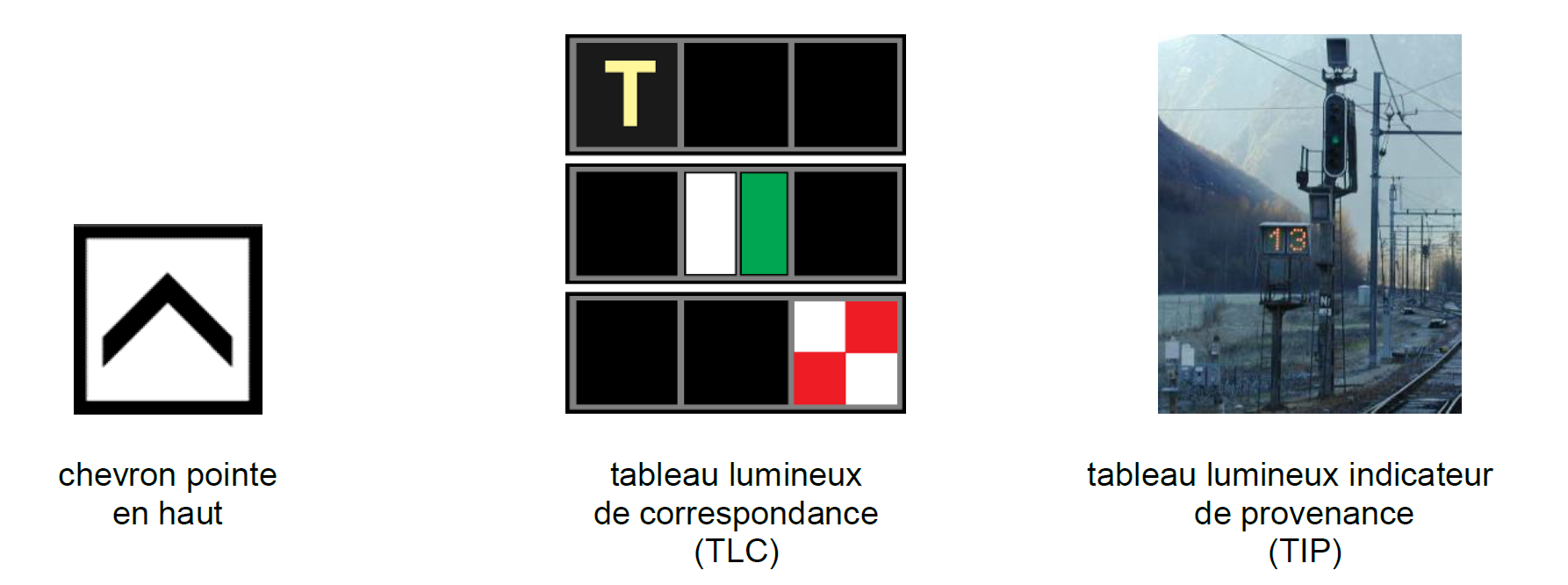
La signalisation de cabine
Sur les lignes à signalisation de cabine, le système transmet de manière continue (ou discontinue) en cabine de conduite des ordres et une consigne de vitesse associée éventuellement à une distance but. La signalisation de cabine peut être complétée par une signalisation au sol dans certains cas pour :
- repérer les points à ne pas dépasser, par exemple :
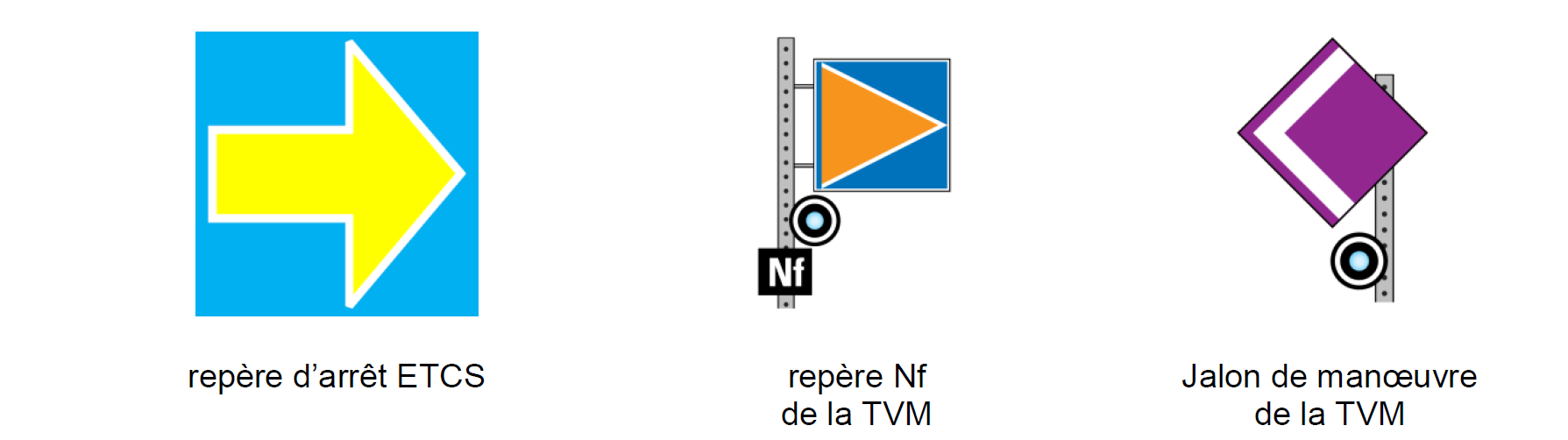
- donner des ordres de traction électrique, des informations aux points d’entrée et de sortie du domaine de signalisation de cabine, etc.
Des pancartes ou tableaux indiquent ces ordres et informations.
Ces repères, pancartes ou tableaux sont implantés :
- à gauche de la voie sur les plateformes à une seule voie ;
- côté piste, à l’extérieur sur les plateformes à deux voies ;
- dans le cas de plan de voie plus complexe, les pancartes ou tableaux sont fléchés.
Nota : les repères ETCS et de la TVM ne sont pas fléchés du fait de leur graphisme indiquant la voie à laquelle ils s’adressent.
Point de transition de signalisation (entrée sur LGV, armement de la signalisation de cabine)
Le point de transition de signalisation (tableau CAB), ainsi que l’armement de la signalisation de cabine, se situent à hauteur ou immédiatement en aval du dernier signal au sol (signal carré).
4.2.3 - Les régimes d’exploitation des lignes
Définition
Ensemble des règles d’exploitation, c’est-à-dire des règles appliquées pour organiser et assurer le trafic, propres à une ligne en fonction des installations mises en œuvre pour en assurer l’exploitation.
Les principaux régimes d’exploitation sont : la voie unique, la voie banalisée, la double voie.
Principe
Il ne faut pas confondre régime d’exploitation et nombre de voies sur une plateforme, car il existe des plateformes à 2 voies qui ne sont pas des « double voie », des plateformes à 3 ou 4 voies qui sont des « double voie », des plateformes à 1 seule voie qui ne sont pas des « voie unique ».
Les appellations et définitions de ces régimes d’exploitation sont donc très importantes, car elles entraînent notamment des contraintes particulières de conduite que ce soit en situation normale ou dégradée (implantation des signaux, marche à vue ou règle spéciale de certains signaux par exemple).
En voie unique, l’organisation de la circulation des trains des deux sens sur une même voie génère un risque spécifique de nez à nez en plus du risque de rattrapage également présent sur les lignes à double voie.
L’exploitation sous le régime de la « double voie » permet, par conception, d’éviter le risque de nez à nez, compte tenu de l’affectation des trains à un sens de circulation par voie. Cependant sur certaines lignes, la circulation des trains s’effectue selon l’un des deux régimes suivants : la voie unique ou la voie banalisée.
4.2.3.1 - Les lignes à une seule voie
Elles sont principalement exploitées selon les dispositions du régime général d’exploitation de la voie unique, certaines d’entre elles disposant d’un minimum d’équipement de signalisation sont désignées « voie unique à signalisation simplifiée ».
D’autres lignes, peu fréquentées et fermées au service voyageur sont exploitées selon le régime de la voie unique à trafic restreint.
Il existe aussi un régime d’exploitation en navette.
Enfin d’autres lignes disposant d’installations de sécurité s’opposant notamment au nez à nez sont exploitées selon le régime de la voie banalisée.
4.2.3.1.1 - La voie unique
Définition
Régime d’exploitation d’une ligne dans lequel les trains des deux sens circulent sur la même voie, les dispositions à prendre pour éviter la rencontre de deux trains de sens contraire ne sont pas automatiques, mais résultent de procédures à appliquer par les personnels affectés à la circulation des trains, voire par les personnels des trains dans certains cas de lignes faiblement équipées. Ces dispositions sont définies par le gestionnaire d’infrastructure.
Principe
Le risque de nez à nez
Les documents horaires sont conçus en respectant des obligations fondamentales telles que le croisement obligatoire de deux trains en gare, qui permettent d’éviter le nez à nez pour les trains de sens contraires.
Ce risque est donc avant tout couvert par le respect de l’ordre normal de circulation des trains figurant aux documents horaires.
En effet, le principe d’exploitation d’une ligne à voie unique s’effectue selon des modalités définies par le gestionnaire d’infrastructure, qui prévoient notamment le respect absolu de l’ordre théorique de succession des trains et en conséquence de l’ordre chronologique d’occupation de la voie unique. Une circulation qui n’est pas à son ordre, ne peut occuper la voie unique sans procédure.
En cas de modification de l’ordre théorique (retard, train supprimé, etc.), des procédures permettent d’organiser le nouvel ordre de circulation des trains (procédures de reports de croisement, dépassements, etc.).
- Le respect des procédures reposant sur l’humain, certaines lignes sont équipées d’une « barrière » technique de sécurité
- le block manuel de voie unique (BMVU - voir 4.4.2.). Des moyens d’arrêt complémentaires (DAAT, GSM/GFU, RST, coupure d’urgence si la ligne est électrifiée, …) peuvent être utilisés ou mis en place afin de réduire les conséquences d’une erreur humaine.
Le risque de rattrapage
Le risque de collision par rattrapage est couvert par le mode de cantonnement. Les différents modes de cantonnement existants sont :
- le cantonnement téléphonique (Voir - 4.3.) ;
- le cantonnement assisté par informatique (CAPI - voir 4.3.) ;
- le cantonnement assisté par informatique initié en 1995 (CAPI 95 - voir 4.3.) ;
- le block manuel de voie unique (BMVU - voir 4.4.2.).
4.2.3.1.2 - La voie unique à signalisation simplifiée (VUSS)
Définition
Certaines lignes à voie unique sont désignées à la documentation d’exploitation comme « Lignes à voie unique à signalisation simplifiée ». Par rapport au régime général de la voie unique, ce type de ligne se distingue par la mise en œuvre d’un minimum d’équipements. Ils se limitent à une pancarte « gare » à distance et à un repère d’entrée.
Principe
Le risque de nez à nez
Elles sont exploitées selon les modalités du régime général d’exploitation de la voie unique (notamment le respect de l’ordre théorique de circulation).
Leur fonctionnement repose en outre sur l’arrêt général des circulations dans toutes les gares.
Le risque de rattrapage
La gestion de l’espacement est assurée par le cantonnement téléphonique.
Il n’y a aucune barrière technique de sécurité, toute erreur humaine peut avoir des conséquences graves. Des boucles de rattrapage peuvent permettre de pallier ces erreurs (DAAT, CAPI, GSM/GFU, RST, coupure d’urgence si la ligne est électrifiée, etc.).
4.2.3.1.3 - La voie unique à trafic restreint (VUTR)
Définition
Ce régime concerne des lignes fermées au service voyageurs qui ne comportent normalement pas de signaux. Les règles concernant le régime général d’exploitation de la voie unique ne sont pas applicables et sont remplacées par des modalités particulières définies par le gestionnaire d’infrastructure.
Principe
Une consigne locale d’exploitation adaptée à chaque VUTR précise les caractéristiques d’exploitation comme la vitesse de la ligne, la signalisation, les établissements, les liaisons téléphoniques, les PN, etc.
Elle est complétée par un programme de circulation qui comporte les horaires des trains devant circuler et précise les dispositions particulières concernant chaque train (trains entre lesquels l’espacement doit être assuré, croisements, etc.).
Ces lignes ne comportent normalement pas de signaux, les limitations de vitesse à observer sur les aiguilles ainsi que les autres limitations permanentes de vitesse sont inscrites à la consigne locale d’exploitation de la ligne ; elles ne sont pas rappelées par des signaux sur le terrain.
Par principe, la vitesse de circulation ne dépasse généralement pas 50 km/h.
Aucun enclenchement n’est prévu. Chaque ligne dépend d’un agent de SNCF Réseau dénommé « chef de ligne ». La sécurité des circulations est assurée par le chef de ligne et par les agents des trains.
Nota : Les VUTR ne sont pas définies dans les RT.
4.2.3.1.4 - L’exploitation en navette
Définition
Régime d’exploitation d’une ligne sur laquelle la circulation d’un train ne peut être autorisée qu’après dégagement du train précédemment engagé, l’engagement et le dégagement se faisant au même point.
Principe
L’exploitation en navette consiste à n’autoriser la présence que d’une seule circulation sur la section de ligne concernée, cette circulation revenant à son point de départ, ce qui par conception limite les risques de collision de trains.
Toutefois, le programme peut inclure moyennant des procédures adaptées des mouvements de desserte, avec ou sans possibilité de garage (desserte origine terminus ou desserte en antenne).
L’accès à la voie exploitée en navette est commandé par un signal muni du DAAT ou du KVB.
4.2.3.1.5 - La voie banalisée
Définition
Régime d’exploitation d’une ligne à une ou plusieurs voies parcourues par les trains des deux sens. Sur ces voies, des installations de sécurité s’opposent à l’expédition de deux trains de sens contraire à la rencontre l’un de l’autre. Sur les lignes à plusieurs voies banalisées, les trains d’un même sens peuvent circuler indifféremment sur l’une quelconque de ces voies.
Principe
Une voie banalisée peut être découpée en plusieurs intervalles (points entre lesquels il n’existe aucune possibilité de croisement ou dépassement).
Sur une voie, quel que soit le sens :
- les signaux sont normalement implantés à gauche ;
- le découpage éventuel d’un intervalle en cantons est identique.
Le risque de nez à nez
Les deux extrémités d’un intervalle de voie banalisée sont équipées de signaux d’arrêt non permissifs permettant d’arrêter et de retenir les trains se dirigeant vers l’intervalle. Elles sont reliées par un enclenchement entre itinéraires de sens contraires.
Le risque de nez à nez est pris en charge notamment, par l’enclenchement entre itinéraires de sens contraire. Cet enclenchement agit directement sur le circuit de commande des signaux de protection donnant accès à l’intervalle. Il nécessite la mise en oeuvre de circuits de voie ou de compteurs d’essieux qui interviennent en outre dans le block automatique (cf. rattrapage ci-dessous).
Les installations de sécurité s’opposent à l’expédition de deux trains de sens contraire dans le même intervalle. Cette interdiction est maintenue tant que l’intervalle est occupé.
Le risque de rattrapage
L’espacement est assuré automatiquement. En signalisation au sol, l’espacement des trains de même sens est assuré par le block automatique par l’intermédiaire de circuits de voie ou de compteur d’essieux. Selon l’importance du trafic, il peut s’agir de :
- BAPR : La longueur d’un canton de BAPR peut atteindre 15 km ou plus ;
- BAL : La longueur maximale d’un canton de BAL n’excède pas généralement 2,8 km ce qui permet un écoulement de trafic plus important.
En signalisation de cabine, la TVM ou l’ETCS assurent l’espacement.
4.2.3.2 - La double voie
Définition
Régime d’exploitation d’une ligne à deux voies (ou plus) dans lequel chaque voie est normalement affectée à la circulation des trains dans un sens déterminé.
Principe
Le risque de nez à nez
Sur une ligne à deux voies, les circulations empruntent normalement la voie de gauche dans le sens de la marche (voie de droite sur les lignes désignées à la documentation d’exploitation).
La double voie est exploitée selon les modalités définies par SNCF Réseau qui prévoit que chaque agent du service de la gestion des circulations doit disposer en temps utile des informations nécessaires pour assurer le service de la circulation des trains, notamment les informations relatives à l’ordre théorique et réel de succession des trains, à l’horaire et aux voies de circulation des trains.
Dans certains cas, il peut être nécessaire (travaux, incidents, etc.) d’organiser la circulation des trains des deux sens sur une seule voie. Les circulations se déplaçant sur une voie en sens inverse du sens normal sont dites à « contresens » sur une installation de contre sens (ICS) ou sur une voie unique temporaire (VUT). Elles sont dites à « contre-voie » dans les autres cas.
En fonction des installations et équipements en place :
- utilisation d’installations qui s’opposent au nez à nez :
- installation de contre sens (ICS) : installations permanentes de contre sens (IPCS) ou installations temporaires de contresens (ITCS) ;
- voie unique temporaire à caractère permanent (VUTP) ;
- ou mise en place de procédures :
Le risque de rattrapage
L’espacement est assuré selon les principes définis dans cette section. Sur une voie les signaux sont normalement implantés à gauche.
4.2.3.2.1 - Les installations de contresens (ICS)
1. Les installations permanentes de contresens (IPCS)
Principe
Certaines sections de ligne comportent des installations permanentes de contresens (IPCS). Ces installations accessibles sans arrêt des trains à l’entrée, permettent à tout moment la circulation des trains à contresens sans que les conducteurs en soient préavisés autrement que par la signalisation.
Le risque de nez à nez
Des enclenchements de sécurité s’opposent à l’expédition de deux trains de sens contraire à la rencontre l’un de l’autre.
Le risque de rattrapage
L’espacement des trains circulant dans le sens normal est assuré dans les conditions habituelles.
L’espacement des trains à contresens est assuré automatiquement.
Avis au conducteur
Les sections de ligne équipées d’IPCS sont désignées aux RT.
La circulation (entrée et sortie) sur IPCS est indiquée au conducteur par la signalisation.
2. Les installations temporaires de contresens (ITCS)
Principe
L’ITCS est un régime temporaire d’exploitation permettant en double voie de faire circuler sur une voie des trains en sens inverse du sens normal.
Ces installations, accessibles sans arrêt des trains à l’entrée, permettent à tout moment la circulation des trains à contresens. Elles sont installées en prévision de chantier de travaux qui vont nécessiter l’obstruction d’une des deux voies.
Le risque de nez à nez
Des enclenchements de sécurité s’opposent à l’expédition de deux trains de sens contraire à la rencontre l’un de l’autre.
Les ITCS ont leurs extrémités dans les gares les plus rapprochées encadrant le chantier de travaux prévu ou bien dans des postes de pleine voie existants ou créés à cet effet, considérés dès lors comme des gares. Si le chantier se déplace, les extrémités de l’ITCS sont reportées au fur et à mesure de la progression du chantier par phases successives, chaque phase faisant l’objet d’une ITCS distincte.
Le risque de rattrapage
L’espacement des trains circulant dans le sens normal est assuré dans les conditions habituelles.
L’espacement des trains à contresens est assuré automatiquement.
Avis au conducteur
Les informations nécessaires aux conducteurs sont fournies par le gestionnaire d’infrastructure aux entreprises ferroviaires. Les particularités de signalisation et d’exploitation de l’ITCS sont mentionnées.
Un schéma adapté à ses besoins peut compléter ces informations.
La circulation (entrée et sortie) sur ITCS est indiquée au conducteur par la signalisation.
3. Circulation à contresens sur une ICS
L’entrée d’un parcours à contresens sur une ICS est repérée par un tableau lumineux d’entrée à contresens (TECS). Ce tableau, normalement éteint, est groupé avec le panneau qui porte le carré protégeant l’aiguille d’entrée.

Exemple d’entrée à contresens à 60 km/h sur une section de ligne où la circulation normale se fait à gauche
Les signaux s’adressant aux conducteurs des trains circulant à contresens sont :
- implantés à droite (disposition inverse sur les lignes où la circulation se fait normalement à droite) ;
- répétés sur les engins moteurs.
Les ICS peuvent comporter à contresens un ou plusieurs cantons.
La sortie d’un parcours à contresens est repérée par un tableau lumineux de sortie de contresens (TSCS). Ce tableau est groupé avec le panneau qui porte le signal « carré » protégeant l’aiguille de sortie.
4.2.3.2.2 - La voie unique temporaire à caractère permanent (VUTP)
Principe
Les installations de voie unique temporaire à caractère permanent (VUTP) permettent la circulation occasionnelle des trains des deux sens sur une seule voie, entre deux gares, sans arrêt à l’entrée et sans préavis aux conducteurs.
Les sections de ligne équipées de VUTP sont désignées aux RT.
Le risque de nez à nez
Des enclenchements de sécurité s’opposent à l’expédition de deux trains de sens contraire à la rencontre l’un de l’autre.
Le risque de rattrapage
L’espacement des trains circulant dans le sens normal est assuré dans les conditions habituelles.
L’espacement des trains à contresens est assuré automatiquement.
Circulation à contresens
L’entrée d’un parcours à contresens est repérée par un tableau VUT groupé avec le panneau qui porte le carré protégeant l’aiguille d’entrée.
La présentation du tableau VUT indique au conducteur :
- que le train est dirigé et est autorisé à s’engager à contresens ;
- qu’à partir de ce tableau, les signaux qui le concernent sont implantés à droite.

Exemple d’entrée à 30 km/h sur VUTP
La vitesse limite à ne pas dépasser est fixée à 70 km/h.
La sortie du parcours à contresens est repérée par un tableau « FIN de VUT » groupé avec le panneau qui porte le signal carré protégeant l’aiguille de sortie.
La présentation du tableau « FIN de VUT » indique au conducteur :
- que le train est parvenu à la fin du parcours à contresens ;
- qu’à partir de ce tableau, les signaux qui le concernent sont implantés à gauche.
4.2.3.2.3 - La voie unique temporaire (VUT)
Principe
Lorsqu’une cause quelconque (incident, exécution de travaux, etc.), interdit l’utilisation d’une voie et en l’absence d’installations permettant la circulation dans les deux sens en sécurité sur l’autre voie (ICS, voie banalisée), la circulation des trains est organisée par les agents du service de gestion des circulations situés aux extrémités selon des procédures adaptées.
La VUT est donc un régime temporaire d’exploitation permettant, sur une ligne à double voie non équipée d’installation de contresens, de faire circuler les trains des deux sens sur une seule et même voie.
Les trains devant circuler à contre sens sont arrêtés à l’entrée.
La circulation sur la VUT dans les deux sens se fait selon le principe de la demande et de l’accord de voie entre agents du service de la gestion des circulations.
La vitesse limite à contre sens est de 70 km/h.
La sortie de la VUT est repérée soit :
- par un signal carré implanté à gauche, à droite ou au-dessus de la voie ;
- par un signal d’arrêt à main.
Organisation
La VUT est établie entre les deux changements de voies utilisables les plus rapprochés qui en constituent les extrémités.
La VUT est organisée par l’agent du service de la gestion des circulations qui expédie les trains à contresens sur cette voie (gare B dans l’exemple ci-dessous) et qui doit aviser ou faire aviser les agents intéressés : agents des postes, des PN gardés, agents travaillant sur la voie ou les caténaires.
Circulation sur la VUT

Le risque de nez à nez
L’expédition de tout train sur la VUT est subordonnée à un accord de voie donné par l’agent du service de gestion des circulations de l’autre extrémité de la VUT à l’agent-du service de gestion des circulations qui doit expédier le train.
Le risque de rattrapage
Les trains de sens normal sont cantonnés dans les conditions habituelles.
Les trains circulant à contresens sont cantonnés téléphoniquement dans les conditions prévues pour la voie unique (voir 4.3.).
Avis au conducteur
En sens normal : aucun avis n’est fait au conducteur, les trains circulent sans arrêt à l’entrée.
À contre sens : le conducteur est arrêté à l’entrée de la VUT puis informé par écrit par l’agent du service de la gestion des circulations qu’il va circuler à contresens en VUT.
Cet ordre écrit reprend les points ou zones du parcours sur lesquels le conducteur doit appliquer des prescriptions particulières.
En effet, les installations et la signalisation ne sont généralement pas prévues pour les circulations en sens inverse du sens normal (PN, limitations de vitesse, etc.).
4.2.3.2.4 - Mouvement à contre-voie
Principe
Lorsqu’une cause quelconque (incident, secours, travaux inopinés de courte durée, etc.), interdit l’utilisation d’une voie, en l’absence d’installation permettant la circulation dans les deux sens sur l’autre voie (ICS, voie banalisée) et qu’il n’est pas envisagé d’organiser une VUT (par exemple, du fait que très peu de circulations seront concernées), la circulation d’un train n’empruntant pas le sens normal se fait alors à contre-voie sur la voie non interceptée. Les trains devant circuler à contre-voie sont arrêtés à l’entrée.
Le mouvement à contre-voie peut être effectué :
- d’un point quelconque vers un point situé en amont (ces points pouvant être un point de pleine voie, une gare, un évitement télécommandé) ;
- à l’intérieur d’une gare.
Organisation
Mouvements à contre-voie à l’intérieur d’une gare
Lorsqu’un mouvement à contre-voie doit être effectué à l’intérieur d’une gare, il est organisé à l’initiative de l’agent du service de gestion des circulations.
Le conducteur est avisé par l’agent du service de la gestion des circulations qu’il doit effectuer un mouvement à contre-voie et que le mouvement s’effectue :
- soit comme une manœuvre. Dans ce cas le conducteur sera renseigné et guidé par des signaux de manœuvre ;
- soit par la transmission d’un ordre écrit ou d’une dépêche.
Autres mouvements à contre-voie
- d’une gare vers la gare en amont ou de la gare en avant vers un point de pleine voie L’agent chargé d’organiser ce mouvement à contre-voie est l’agent du service de gestion des circulations de la gare dans laquelle le mouvement a son origine.
- d’un point de pleine voie vers la gare en arrière L’agent chargé d’organiser ce mouvement à contre-voie est l’agent du service de gestion des circulations de la gare dans laquelle le mouvement se termine. Dans ces deux cas, l’agent du service de la gestion des circulations, après avoir obtenu l’assurance que la partie de voie à parcourir est libre et le restera, remet un ordre écrit ou transmet une dépêche au conducteur pour circuler à contre-voie.
- En pleine voie
Le conducteur est responsable de ce mouvement, lorsqu’il prend l’initiative d’exécuter ce mouvement :
- à la suite d’une rupture d’attelage lorsque le train peut être reconstitué ;
- à la suite d’un léger dépassement du point d’arrêt habituel dans un établissement PL.
Circulation à contre-voie
Après arrêt du train, l’agent du service de la gestion des circulations, selon le cas, remet au conducteur un ordre écrit ou le transmet par dépêche. Cet ordre reprend les points ou zones du parcours sur lesquels le conducteur doit appliquer des prescriptions particulières.
En effet, les installations et la signalisation ne sont généralement pas prévues pour les circulations en sens inverse du sens normal (PN, limitations de vitesse, etc.).
Lorsque le conducteur est en tête du mouvement, la circulation s’effectue en marche à vue sur tout le parcours effectué à contre-voie (le conducteur peut rencontrer un obstacle non protégé).
Lorsque le conducteur n’est pas en tête, la circulation est guidée par des signaux de manœuvre.
La fin du parcours à contre voie est généralement repérée soit :
- par un signal carré ;
- par un signal d’arrêt à main.
4.2.4 - Les systèmes d'espacement des trains
Définition
Le système d’espacement des trains de même sens, est destiné à éviter les rattrapages et consiste à fractionner la ligne en plusieurs cantons dont l’entrée est protégée par un signal d’arrêt.
Principe
Compte tenu de leur masse importante, de leur vitesse élevée, de la faible adhérence rail-roue, les trains ont besoin d’une distance importante pour s’arrêter.
De ce fait, la distance nécessaire pour obtenir l’arrêt est généralement plus grande que la partie de voie visible par le conducteur. Dans ces conditions, le conducteur d’un train en marche ne voyant pas à temps la queue d’un train arrêté ou circulant à plus faible vitesse devant lui risquerait de le heurter.
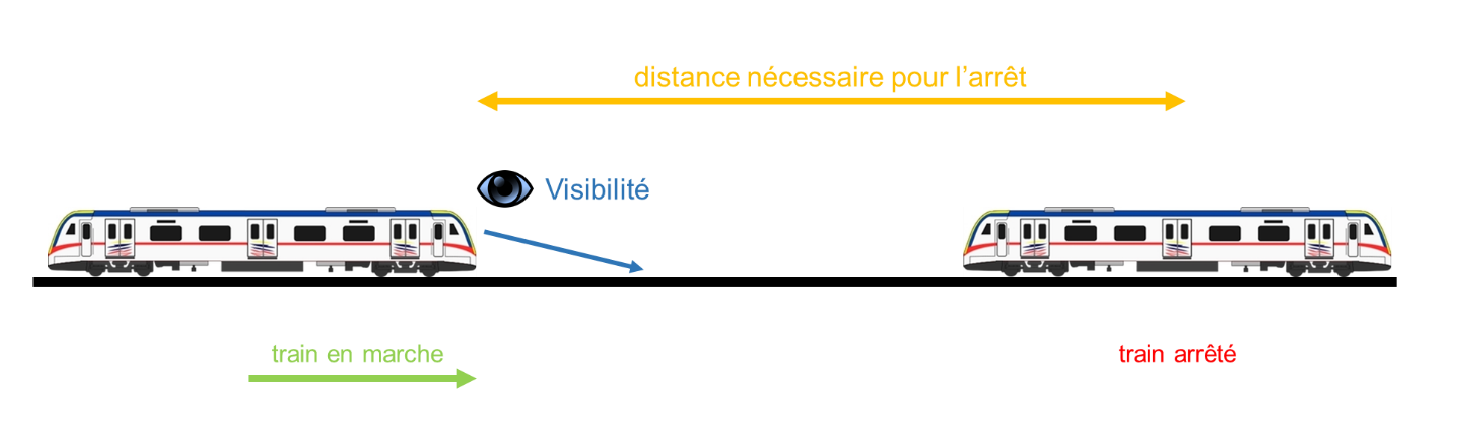
Pour prévenir le risque de rattrapage : un dispositif d’espacement des trains appelé « cantonnement » est mis en place selon les principes suivants :
- la ligne est divisée en portions de voie appelées « cantons »
- l’entrée de chaque canton est normalement commandée par un signal
- un seul train est normalement admis dans chaque canton
- aucun train ne peut normalement pénétrer dans un canton occupé, du fait du maintien à la fermeture du signal d’entrée du canton durant tout le temps de son occupation
Dans certains cas particuliers, la pénétration d’un train dans un canton occupé ainsi que les modalités de franchissement du signal d’entrée du canton sont prévues dans une procédure propre à chaque mode de cantonnement.
Les différents modes de cantonnement
On distingue :
- le cantonnement téléphonique
- le block manuel par appareils (BM)
- le block automatique : lumineux (BAL) ou à permissivité restreinte (BAPR)
- l’ETCS 1 généralement superposé à la signalisation au sol
- l’espacement sur lignes à grande vitesse (TVM, ETCS 2)
Sur les sections de lignes équipées en cantonnement téléphonique ou en block manuel par appareils, les signaux de cantonnement sont manœuvrés au sol ou depuis des postes par des agents du service du gestionnaire d’infrastructure (GI) chargé de la gestion des circulations dénommés « gardes ».
Sur les sections de lignes équipées en BAL ou BAPR, les signaux de cantonnement se ferment automatiquement dès l’occupation du canton et restent fermés jusqu’à sa complète libération.
Sur les sections de lignes à signalisation de cabine, équipées en TVM ou ETCS, les informations liées à l’espacement des trains sont données au conducteur automatiquement directement en cabine de conduite.
Pour déterminer le mode et le cas échéant les postes de cantonnement d’une section de ligne, il faut consulter les RT.
4.2.4.1 - BA
Block Automatique
Principe
Le block automatique se caractérise en block automatique lumineux (BAL) et en block automatique à permissivité restreinte (BAPR) par :
- le fonctionnement entièrement automatique des signaux de cantonnement dont le changement d’état (fermeture ou ouverture) est provoqué par le passage des circulations sans aucune intervention humaine ;
- l’état d’occupation de chaque canton, agissant directement sur le signal d’entrée correspondant est obtenu par le circuit de voie en BAL, généralement par un comptage d’essieu en BAPR. Le BAL permet un débit élevé des circulations sur la ligne.
Fonctionnement d’un circuit de voie
Un circuit de voie est principalement constitué de trois éléments :
- un émetteur, branché à l’une des extrémités de la zone. Il délivre un courant qui peut être de différente nature selon les types de circuit de voie (continu, impulsionnel, alternatif, etc.) ;
- une ligne de transmission, constituée par les deux files de rails ;
- un récepteur, branché à l’autre extrémité de la zone. Il assure le filtrage, l’amplification et la transformation du signal reçu via les rails, ce qui agit sur un relais appelé relais de voie. Les contacts de ce relais sont utilisés pour établir ou couper le circuit électrique du signal d’entrée du canton.
Lorsqu’aucun véhicule n’est présent sur la zone délimitant le circuit de voie (voie libre), le signal délivré par l’émetteur parvient au récepteur à travers la ligne de transmission, et le relais de voie est excité. Le feu d’entrée du canton est à voie libre (cas 1 ci-dessous).
Lorsqu’un véhicule est présent, son premier essieu agit comme une faible résistance, appelée shunt, qui court-circuite la transmission. Dans ce cas, le niveau du signal parvenant au récepteur n’est plus suffisant et le relais de voie se désexcite, ce qui entraine la fermeture du signal d’entrée du canton (cas 2 ci-dessous).
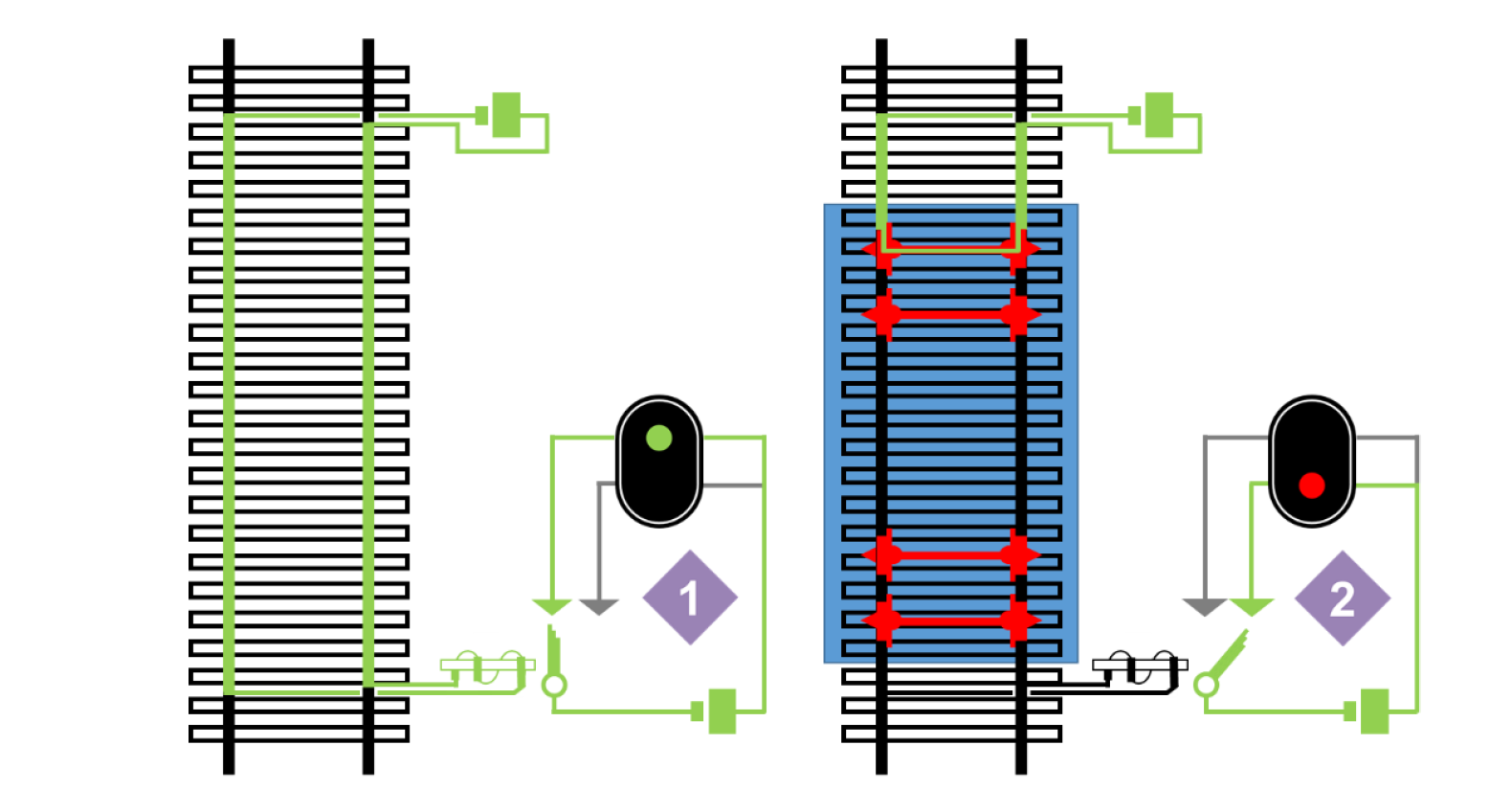
Fonctionnement des compteurs d’essieux
Un compteur d’essieux est un dispositif technique servant à détecter la présence d’une circulation sur une section, par comptage des essieux qui franchissent les détecteurs encadrant cette section.
Un point de détection est installé à chaque extrémité de la section, et chaque fois qu’un essieu passe sur ce point au début de la section, un compteur s’incrémente. Quand le train passe sur le point de détection en fin de la section, le compteur décrémente. Si le nombre final est zéro, la section est présumée libre pour un deuxième train et le signal d’entrée du canton présentera l’indication « voie libre ».
4.2.4.1.1 - BAL
Block Automatique Lumineux
Le signal d’entrée du canton présente une indication liée à l’état d’occupation du ou des cantons suivants, selon les règles suivantes :
- indication d’arrêt lorsque le canton est occupé par au moins une portion du train
- annonce lorsque le canton suivant est occupé
- voie libre par défaut (sauf signaux Nf)
La longueur maximale d’un canton est en principe de 2800 m. Elle est généralement de 1500 m sur les lignes parcourues à la vitesse maximale de 160 km/h.
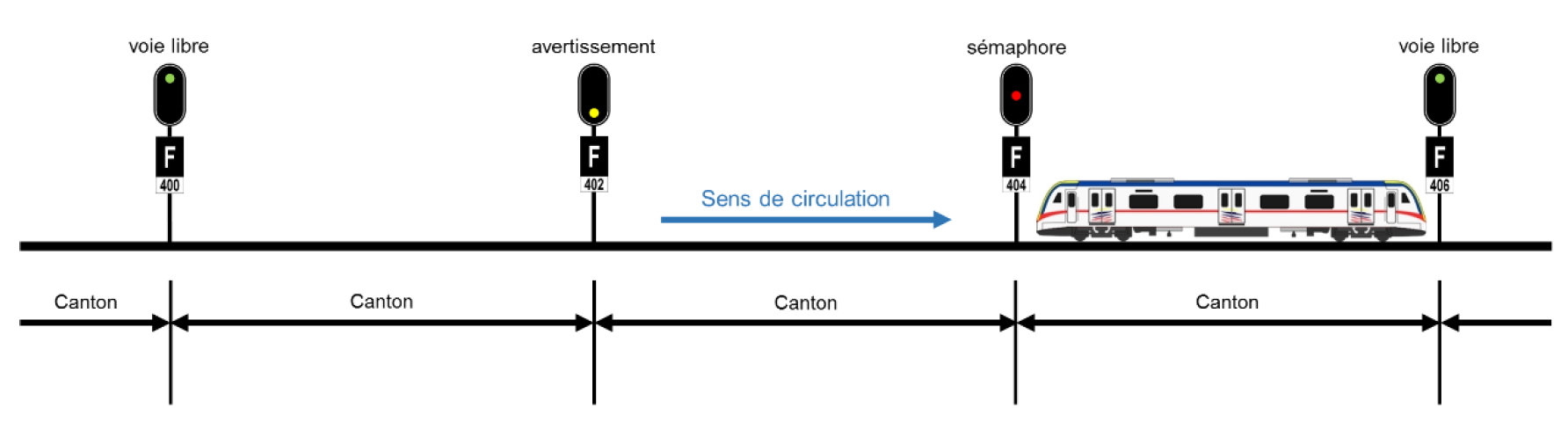
Avantages du BAL
Le BAL offre un niveau élevé de sécurité et permet un débit important.
Limites
L’installation du BAL est très coûteuse, et son fonctionnement nécessite une garantie de contact électrique entre la roue et le rail.
Implémentation
Simuler correctement le système BAL nécessite de respecter les critères suivants :
- lorsque la tête du train pénètre dans un canton, le signal d’entrée de celui-ci passe en indication d’arrêt
- lorsque la queue du train libère un canton, son signal d’entrée passe en annonce
- lorsque la queue du train libère un canton, le signal d’entrée du canton précédent passe en voie libre
- les signaux présentent une voie libre par défaut, sauf les signaux Nf qui sont par défaut en indication d’arrêt
4.2.4.1.2 - BAPR
Block Automatique à Permittivité Restreinte
Le signal d’entrée du canton est un signal qui présente une indication liée à l’état d’occupation du canton suivant (indication d’arrêt ou de voie libre). Sur certaines lignes l’occupation du canton n’est pas obtenue par le circuit de voie mais par un système de comptage d’essieux entrants et sortants.
Les cantons sont beaucoup plus longs que le BAL (jusqu’à 15 km et plus) et par conséquent le débit est moins important.
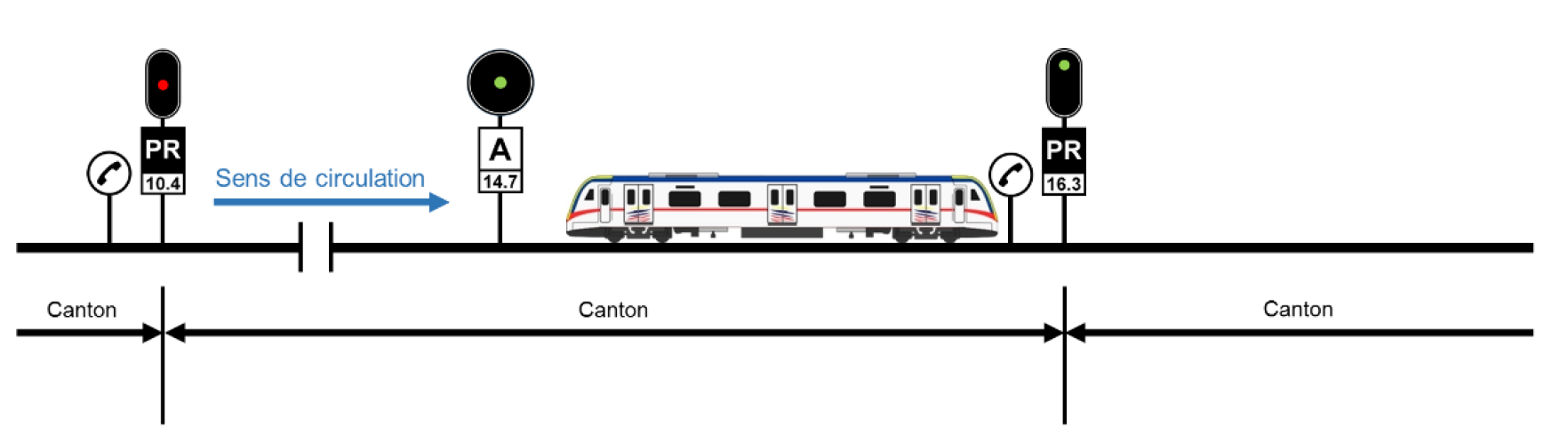
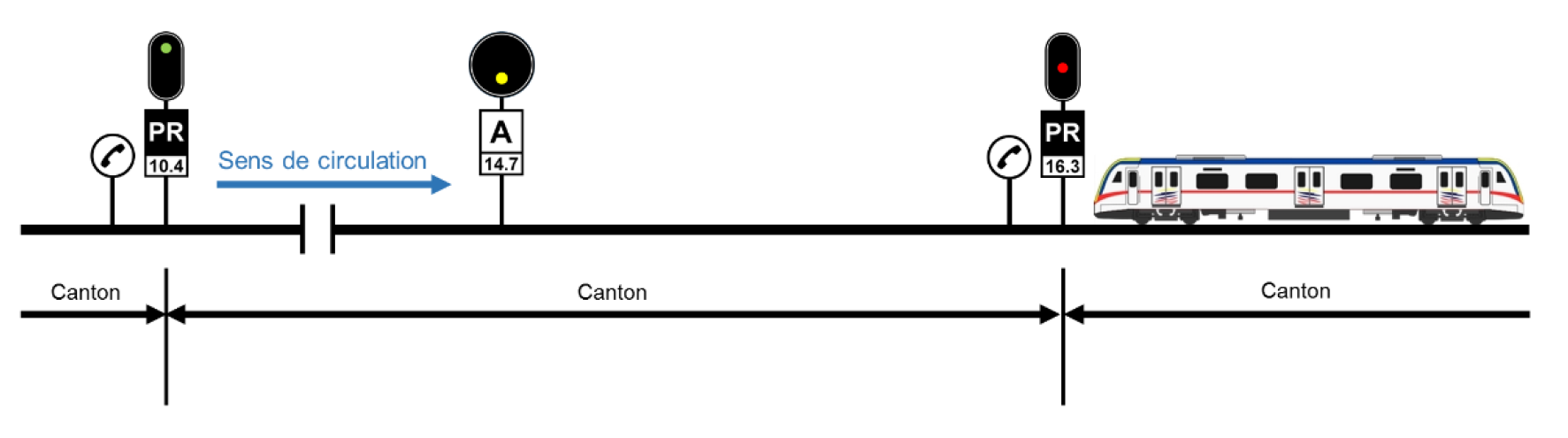
Avantages du BAPR
Le BAPR offre un bon niveau de sécurité et il est moins coûteux que le BAL.
Limites
Ce type de block n’est adapté qu’aux lignes conventionnelles à trafic moyen compte tenu de l’espacement imposé entre 2 trains successifs.
4.2.4.2 - ERTMS
European Rail Traffic Management System
Introduction
L’ERTMS, pour European Rail Traffic Management System, est un système qui vise à harmoniser la signalisation ferroviaire en Europe.
Il est composé de trois sous-systèmes :
4.2.4.2.1 - ETCS
European Train Control System
Généralités
ETCS est le système européen de contrôle commande des trains. La partie bord est interopérable. La partie sol peut être différente selon les pays tout en répondant aux mêmes objectifs de fonctionnalité.
Il existe quatre niveaux différents dont deux sont en service : L’ETCS 1 et L’ETCS 2. L’ETCS 0 est interdit en France. L’ETCS 3 est encore à l’état de développement dans la plupart des pays de l’Union européenne.
Il s’agit d’un système de signalisation de cabine et de contrôle de vitesse faisant appel aux trois composantes suivantes :
- sol : pour la gestion des circulations comprenant notamment l’espacement, la protection des points à protéger et des circulations
- bord : pour l’affichage des ordres et informations à destination du conducteur et le contrôle de la bonne exécution de ceux-ci, dénommé EUROCAB
- liaison : pour les échanges de données entre le sol et le bord :
Sur le RFN, sont mis en oeuvre les niveaux d’exploitations suivants :
L’ETCS1 sur certaines lignes parcourables jusqu’à 220 km/h. Il correspond à un système de signalisation de cabine, généralement superposé à la signalisation au sol existante, dont les informations entre le sol et le bord sont transmises ponctuellement par eurobalise.
L’ETCS2 sur certaines lignes à grande vitesse. Il correspond à un système de signalisation de cabine dont les informations entre le sol et le bord sont transmises en temps utile ou cycliquement par liaison permanente GSM-R DATA.
L’ETCS2 est un système qui ne nécessite pas la matérialisation des cantons sur le terrain.
Préalablement à tout déplacement, les données relatives au train doivent être saisies ou paramétrées à bord. Ainsi, le système peut, à partir des données bord et sol, superviser le train, c’est-à-dire contrôler sa vitesse et ses déplacements et intervenir en cas de nécessité.
La détection d’une circulation sur une partie de voie est réalisée au moyen de circuits de voie ou de compteurs d’essieux. En ETCS2, la combinaison des équipements sol et bord est telle qu’elle ne nécessite, normalement, pas de signalisation complémentaire au sol.
Équipement bord
Le bord est constitué d’un DMI, d’un EVC, de capteurs odométriques (de vitesse), d’antennes pour la lecture des PI ETCS, un modem GSM-R (Euroradio) pour ETCS2, d’une unité juridique d’enregistrement des paramètres d’exploitation, d’interfaces avec le train.
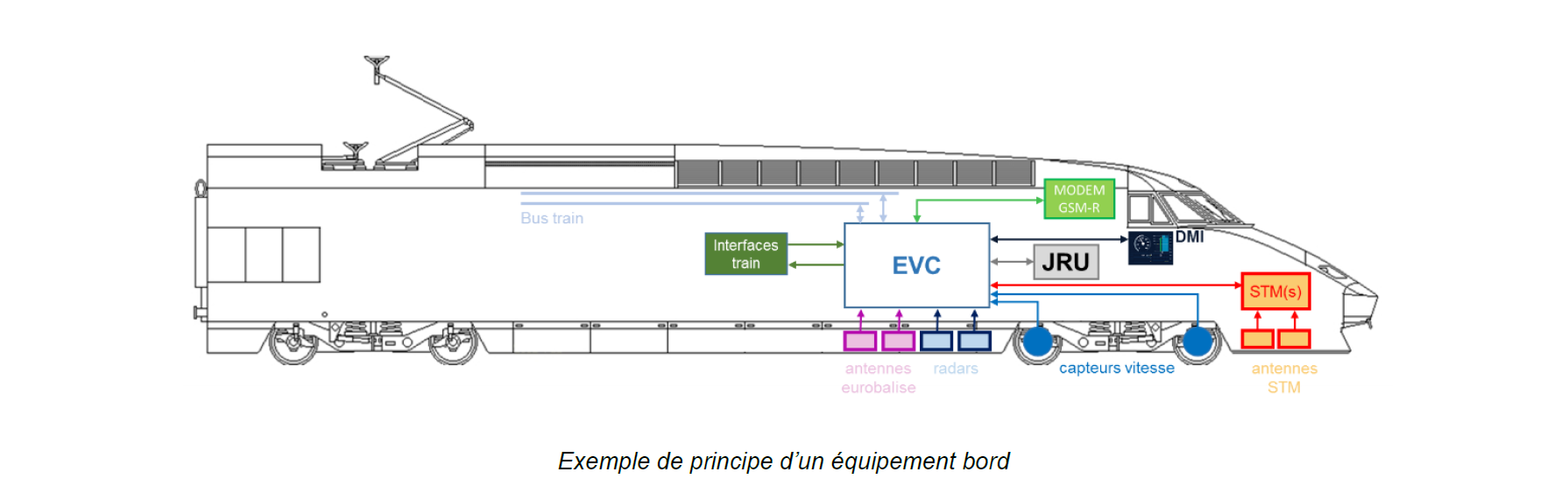
Le DMI
Le DMI est l’interface entre le conducteur et la machine. Il permet d’afficher les ordres et instructions en fonction des données sol et/ou bord. Le conducteur renseigne également le système par saisie de données.
L’espacement des circulations et la protection des points dangereux se traduisent par l’affichage en temps utile d’une vitesse but et d’une distance but. La vitesse but doit être respectée par le conducteur au point défini par la distance but.
En « marche normale », le DMI indique au conducteur la vitesse autorisée qui ne doit pas être dépassée. Dans ce cas, il n’y a pas d’affichage de la distance but et de la vitesse but.
Un secteur pouvant présenter différentes couleurs est utilisé pour indiquer les ordres de vitesse ou d’arrêt.
Enfin, d’autres indications sont affichées telles que la signalisation de traction électrique, le niveau d’exploitation, le mode technique. Les changements d’indication au DMI peuvent être accompagnés d’indications sonores. Une zone en partie basse du DMI est également réservée pour l’affichage de messages textuels. Certaines informations complémentaires peuvent également être affichées par l’entreprise ferroviaire.

Dans cet exemple, le conducteur autorisé à circuler à 140 km/h maximum, circule à 125 km/h, il va devoir observer une phase de ralentissement afin de respecter la vitesse maxi de 100 km/h (vitesse But) à une distance de 2850 mètres (distance But).
Le DMI utilise un code couleur, avec la signification suivante :
- blanc/gris clair/gris foncé : aucune action immédiate n’est exigée du conducteur
- jaune : le conducteur doit intervenir si la vitesse réelle est proche de la vitesse autorisée (risque de passer à la couleur orange en l’absence de réaction)
- orange : l’intervention est insuffisante (risque de passer à la couleur rouge en l’absence de réaction du conducteur)
- rouge : réaction trop tardive du conducteur, prise en charge par le système (peut revenir au jaune, au gris ou au blanc après une action appropriée)
ETCS niveau 1
Transmission sol-bord
Ce niveau utilise une transmission ponctuelle à l’aide de balises placées au pied des signaux et en amont. Ces balises (eurobalises) communiquent les données de signalisation au train.
Détection des trains
Le niveau 1 nécessite l’utilisation d’un système de détection des trains au sol (tel que des circuits de voie, compteurs d’essieux et autres). Toutes ces informations sont donc transmises ponctuellement au train. La cadence de l’information donnée pouvant être augmentée en jouant sur le nombre de balises, ou en installant une boucle (euroloop), équivalent d’une balise, mais longeant la ligne sur une certaine distance.
ETCS niveau 2
Transmission sol-bord
Les données de signalisation sont transmises de manière permanente, via le réseau GSM-R. Le train communique constamment sa position (qu’il détermine avec un odomètre) au centre de contrôle qui lui communique en retour les actions à effectuer (vitesse, arrêt, etc.).
Des eurobalises sont toujours présentes sur la voie pour recaler éventuellement l’odométrie embarquée.
Détection des trains
Un système de détection des trains au sol s’appuie sur l’existence des circuits de voie pour localiser un train aval sur un canton. Cette information est transmise au radio block center (RBC) qui gère ensuite l’espacement entre deux circulations. Le train suiveur reçoit une nouvelle autorisation de circulation par l’intermédiaire de la liaison radio GSM-R. Dès que le train aval libère un canton le poste central de commande reçoit l’information correspondante du sol qui est transmise par liaison radio au train suiveur.
Avantage
Le niveau 2 rend disponible quasi immédiatement une information « libératoire » pour le train suiveur et contribue ainsi à augmenter la fluidité. Cette immédiateté est la différence par rapport à la signalisation conventionnelle, où une demi-minute est parfois nécessaire pour libérer un aiguillage alors que le train est déjà bien loin.
Les modes techniques
Les modes techniques utilisés sur le RFN sont :
Mode FS : Conduite en supervision complète.
Toutes les données train et voie sont disponibles à bord.
Le DMI affiche :
- la vitesse réelle du train et la vitesse autorisée
- lors de l’approche d’un EOA, d’un repère d’arrêt ETCS ou un heurtoir, la vitesse but et la distance but
Le système « bord » supervise la vitesse, le déplacement du train, le respect de l’EOA matérialisé par un repère d’arrêt ETCS, un signal d’arrêt ou un heurtoir en ETCS1.
Mode OS : Conduite en marche à vue.
Toutes les données train et voie sont disponibles à bord sauf l’assurance de la libération de toute ou partie de la voie allouée au train.
Le DMI affiche les mêmes indications qu’en mode FS.
Le système « bord » assure également la supervision comme en mode FS.
Mode SR : Conduite sous la responsabilité des agents.
Ce mode technique est utilisé pour les situations dégradées et la procédure « Mise en service » lorsque le bord n’a pas reçu d’allocation de voie. Le système « bord » ne supervise que la vitesse du mode SR et le franchissement des repères d’arrêt ETCS et des signaux d’arrêt.
Mode SH : Circulation en manœuvre.
Ce mode technique est sélectionné par le conducteur pour les mouvements de manœuvre. Le système « bord » ne supervise que la vitesse du train.
Mode NL : Conduite d’un engin moteur non en tête du mouvement
Ce mode technique est utilisé en cas de pousse ou de double traction.
Protection contre le rattrapage
En mode FS, une vitesse autorisée affichée sans la présentation de l’EOA signifie « marche normale ».
La MA constituée d’un ou plusieurs cantons est allouée canton par canton, par ajout successif d’un canton. Si le canton en aval du dernier canton alloué est occupé le train doit être en mesure de s’arrêter avant l’entrée de ce canton. Le conducteur est alors avisé par une indication sonore au DMI.
Dès lors, les indications de conduite (vitesse but égale à 0 et une distance but) permettant de respecter la courbe de freinage sont affichées.
Le conducteur doit ralentir de façon à être en mesure de s’arrêter avant l’EOA, tout en respectant la vitesse autorisée.
4.2.4.2.2 - GSM-R
Global System for Mobiles - Railways
4.2.4.2.3 - GPRS
General Packet Radio Service
4.2.4.2.4 - FRMCS
Futur Système de Communications Mobiles Ferroviaires
4.2.4.2.5 - ETML
European Train Management Layer
4.2.4.3 - Signalisation Ks
Non traduit : veuillez sélectionner une autre langue.
4.2.4.3.1 - Linienförmige Zugbeeinflussung (LZB)
Non traduit : veuillez sélectionner une autre langue.
4.2.4.3.2 - Punktförmige Zugbeeinflussung (PZB)
Non traduit : veuillez sélectionner une autre langue.